

Différence entre l'ensachage et la forêt aléatoire
- 4182
- 1284
- Elisa Petit
Au fil des ans, plusieurs systèmes de classificateurs, également appelés systèmes d'ensemble, ont été un sujet de recherche populaire et ont apprécié une attention croissante au sein de la communauté de l'intelligence informatique et de l'apprentissage automatique. Il a attiré l'intérêt des scientifiques de plusieurs domaines, notamment l'apprentissage automatique, les statistiques, la reconnaissance des modèles et la découverte de connaissances dans les bases de données. Au fil du temps, les méthodes d'ensemble se sont révélées très efficaces et polyvalentes dans un large éventail de domaines problématiques et d'applications du monde réel. Développé à l'origine pour réduire la variance du système de prise de décision automatisé, des méthodes d'ensemble ont depuis été utilisées pour résoudre une variété de problèmes d'apprentissage automatique. Nous présentons un aperçu des deux algorithmes d'ensemble les plus importants - l'ensachage et la forêt aléatoire - puis discutons des différences entre les deux.
Dans de nombreux cas, l'ensachage, qui utilise un échantillonnage de bootstrap, il a été démontré que les tresses de classification ont une précision plus élevée qu'un seul arbre de classification. L'achat est l'un des algorithmes basés sur des ensembles les plus anciens et les plus simples, qui peuvent être appliqués aux algorithmes à base d'arbres pour améliorer la précision des prédictions. Il y a encore une autre version améliorée de l'ensachage appelé algorithme Random Forest, qui est essentiellement un ensemble d'arbres de décision formés avec un mécanisme d'ensachage. Voyons comment fonctionne l'algorithme de forêt aléatoire et en quoi est-ce différent de l'achat dans les modèles d'ensemble.
Engage
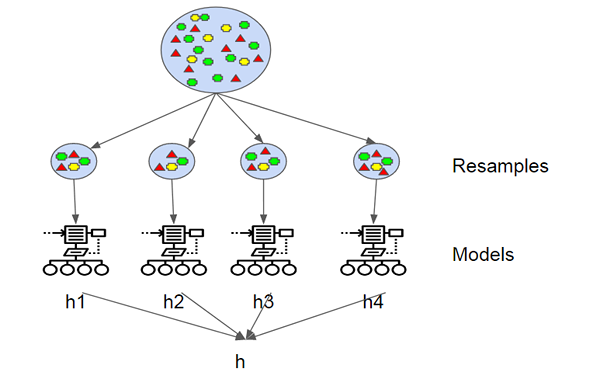
L'agrégation de bootstrap, également connue sous le nom de sacs, est l'un des algorithmes d'ensemble les plus anciennes et les plus simples pour rendre les arbres de décision plus robustes et pour obtenir de meilleures performances. Le concept derrière l'ensachage est de combiner les prédictions de plusieurs apprenants de base pour créer une sortie plus précise. Leo Breiman a introduit l'algorithme d'ensachage en 1994. Il a montré que l'agrégation bootstrap peut apporter des résultats souhaités dans des algorithmes d'apprentissage instables où de petits changements aux données de formation peuvent provoquer de grandes variations dans les prévisions. Un bootstrap est un échantillon d'un ensemble de données avec remplacement et chaque échantillon est généré en échantillonnant uniformément l'ensemble de formation de taille M jusqu'à ce qu'un nouvel ensemble avec M est obtenu.
Forêt aléatoire
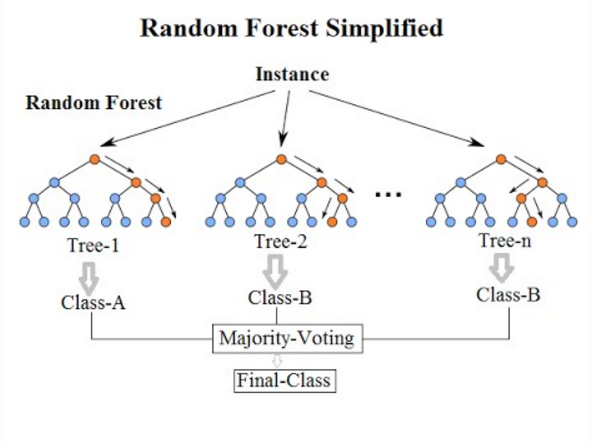
Random Forest est un algorithme d'apprentissage automatique supervisé basé sur l'apprentissage d'ensemble et une évolution de l'algorithme d'agitation d'origine de Breiman. C'est une grande amélioration par rapport aux arbres de décision en sac afin de construire plusieurs arbres de décision et de les agréger pour obtenir un résultat précis. Breiman a ajouté une variation aléatoire supplémentaire dans la procédure d'ensachage, créant une plus grande diversité parmi les modèles résultants. Les forêts aléatoires diffèrent des arbres en sac en forçant l'arbre à utiliser seulement un sous-ensemble de ses prédicteurs disponibles à se séparer en phase de croissance. Tous les arbres de décision qui composent une forêt aléatoire sont différents car chaque arbre est construit sur un sous-ensemble aléatoire différent de données. Parce qu'il minimise le sur-ajustement, il a tendance à être plus précis qu'un seul arbre de décision.
Différence entre l'ensachage et la forêt aléatoire
Bases
- Les forêts d'ensachage et aléatoires sont des algorithmes basés sur des ensembles qui visent à réduire la complexité des modèles qui surfident les données de formation. L'agrégation bootstrap, également appelée l'ensachage, est l'une des méthodes d'ensemble les plus anciennes et les plus puissantes pour empêcher le sur-ajustement. C'est une méta-technique qui utilise plusieurs classificateurs pour améliorer la précision prédictive. L'achat signifie simplement tirer des échantillons aléatoires de l'échantillon d'entraînement pour le remplacement afin d'obtenir un ensemble de modèles différents. Random Forest est un algorithme d'apprentissage automatique supervisé basé sur l'apprentissage d'ensemble et une évolution de l'algorithme d'agitation d'origine de Breiman.
Concept
- Le concept d'échantillonnage de bootstrap (engage) consiste à former un tas d'arbres de décision non composés sur différents sous-ensembles aléatoires des données de formation, échantillonnage par le remplacement, afin de réduire la variance des arbres de décision. L'idée est de combiner les prédictions de plusieurs apprenants de base pour créer une sortie plus précise. Avec des forêts aléatoires, une variation aléatoire supplémentaire est ajoutée à la procédure d'ensachage afin de créer une plus grande diversité parmi les modèles résultants. L'idée derrière les forêts aléatoires est de construire plusieurs arbres de décision et de les agréger pour obtenir un résultat précis.
But
- Les arbres en sac et les forêts aléatoires sont les instruments d'apprentissage d'ensemble les plus courants utilisés pour résoudre une variété de problèmes d'apprentissage automatique. L'échantillonnage de bootstrap est un méta-algorithme conçu pour améliorer la précision et la stabilité des modèles d'apprentissage automatique en utilisant l'apprentissage de l'ensemble et réduire la complexité des modèles de sur-ajustement. L'algorithme de forêt aléatoire est très robuste contre le sur-ajustement et il est bon avec les données déséquilibrées et manquantes. C'est également le choix préféré de l'algorithme pour construire des modèles prédictifs. L'objectif est de réduire la variance en faisant la moyenne de multiples arbres de décision profonds, formés sur différents échantillons des données.
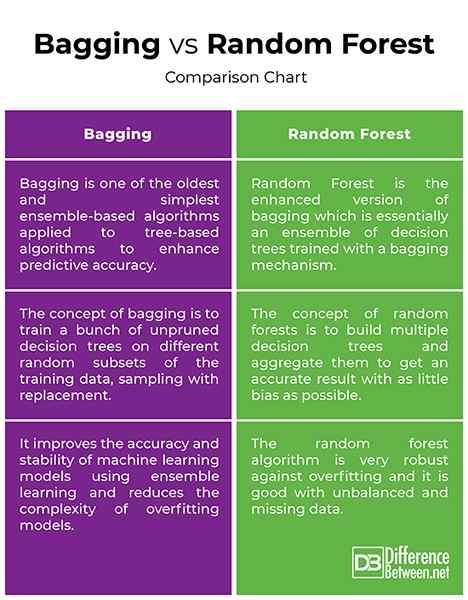
Esachant VS. Forest aléatoire: tableau de comparaison
Résumé
Les arbres en sac et les forêts aléatoires sont les instruments d'apprentissage d'ensemble les plus courants utilisés pour résoudre une variété de problèmes d'apprentissage automatique. L'achat est l'un des algorithmes basés sur des ensembles les plus anciens et les plus simples, qui peuvent être appliqués aux algorithmes à base d'arbres pour améliorer la précision des prédictions. Les forêts aléatoires, en revanche, sont un algorithme d'apprentissage automatique supervisé et une version améliorée du modèle d'échantillonnage bootstrap utilisé à la fois pour les problèmes de régression et de classification. L'idée derrière Random Forest est de construire plusieurs arbres de décision et de les agréger pour obtenir un résultat précis. Une forêt aléatoire a tendance à être plus précise qu'un seul arbre de décision car il minimise le sur-ajustement.
- « Différence entre le chien de garde numérique et Hikvision
- Différence entre la bronchite et la bronchectasie »