

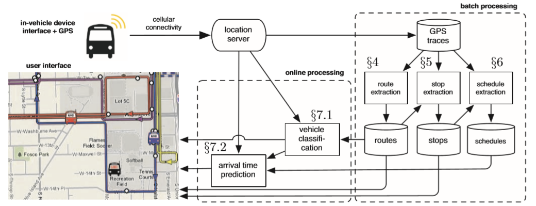
Différence entre le traitement par lots et le traitement des flux
- 3078
- 870
- Adrien Jean
Les données sont la nouvelle monnaie de l'économie numérique d'aujourd'hui. De nombreuses organisations tirent parti des mégadonnées et des technologies de cloud pour améliorer l'infrastructure informatique traditionnelle et soutiennent la culture et la prise de décision basées sur les données lors de la modernisation des centres de données. Cependant, la virtualisation et l'automatisation ne sont qu'une partie de la transition vers un environnement cloud. Les approches pour répondre aux demandes croissantes des entreprises doivent être adaptées à l'entreprise. Bien que le cloud computing ne soit rien de moins qu'un changement révolutionnaire dans l'industrie et que les technologies basées sur le cloud soient la clé pour assurer une structure de gestion des données sophistiquée, le défi est de savoir comment faire en sorte que les données soient traitées plus rapidement - traitement par lots ou traitement de flux. Chacun a ses avantages et ses inconvénients, mais tout se résume à votre cas d'utilisation de l'entreprise. Jetons un coup d'œil aux deux approches et découvrons les différences entre les deux.
Qu'est-ce que le traitement par lots?
Le traitement par lots est une méthode de traitement des volumes élevés de données dans un groupe ou un lot dans un intervalle spécifique. Les systèmes exécutent une série de programmes qui prennent un ensemble de fichiers de données en entrée, traitent les données et produisent un ensemble de fichiers de données en sortie. Un bon exemple de traitement par lots est les systèmes de paie et de facturation où toutes les données connexes sont collectées et détenues jusqu'à ce que la facture soit traitée comme un lot à la fin de chaque mois. Il s'agit du traitement des blocs de données qui ont déjà été stockés sur une période spécifique. Il est ainsi appelé parce que les données sont collectées en lots sous forme d'ensembles d'enregistrements et traités comme une unité. La sortie est un autre lot qui peut être réutilisé en entrée si nécessaire. La simplicité et la sophistication du système de lots permet également un traitement parallèle, e.g., Hadoop.
Qu'est-ce que le traitement des flux?
Le traitement du flux est une méthode utilisée pour interroger le flux continu de données et détecter rapidement les conditions dans une période limitée. En d'autres termes, le traitement des flux est le traitement des données directement tel qu'il est produit ou reçu. Les systèmes de traitement de flux se nourrissent souvent des actions qui se produisent en temps réel telles que les messages des médias sociaux, les clics de pages Web, les transactions de commerce électronique, les lectures de capteurs, etc. Ces systèmes devraient avoir un taux de traitement plus rapide que le taux de données entrantes. L'idée de base du traitement des flux est que les systèmes sont censés être de longue date, traitant d'un flux continu de données. Pour gagner de la valeur des mégadonnées, les données doivent être traitées dès leur arrivée tout en maintenant la qualité des données. Un traitement efficace de flux peut résoudre une grande variété de problèmes du monde réel. Par exemple, le flux peut être utilisé pour la détection de fraude, la prise de décision, l'apprentissage des modèles, etc.
Différence entre le traitement par lots et le traitement des flux
Définition
- Le traitement par lots est une méthode de traitement des volumes élevés de données dans un groupe ou un lot dans un délai spécifique. Il est appelé traitement par lots car les données sont collectées en lots en tant qu'ensembles d'enregistrements et traités comme une unité. La sortie est un autre lot qui peut être réutilisé en entrée si nécessaire. Le traitement du flux, en revanche, est une méthode de traitement des données directement telle qu'elle est produite ou reçue. Il est utilisé pour interroger un flux continu de données et détecter rapidement les conditions dans une période limitée.
Modèle
- Dans le traitement par lots, le système exécute une série de programmes qui prennent un ensemble de fichiers de données en entrée, traitent les données et produisent un ensemble de fichiers de données en sortie. Le composant d'entrée est chargé de collecter des données à partir de plusieurs sources, généralement des bases de données, et le composant de traitement est responsable de la réalisation de calculs en utilisant ces entrées. Enfin, le composant de sortie génère des résultats qui sont écrits dans les bases de données. Dans le traitement des flux, le système effectue un traitement sur l'enregistrement le plus récent de données signifiant que les systèmes se nourrissent des actions qui se produisent en temps réel.
Exemple
- Le meilleur exemple de systèmes de traitement par lots est les systèmes de paie et de facturation dans lesquels toutes les données connexes sont collectées et détenues jusqu'à ce que la facture soit traitée comme un lot à la fin de chaque mois. De nombreuses plates-formes de programmation distribuées comme MapReduce, Spark, GraphX et HTCondor sont des systèmes de traitement par lots. Le traitement des flux peut être utilisé comme une solution en ligne pour la détection de fraude et utilisé pour les applications qui nécessitent une production continue à partir de données entrantes comme le marché boursier, les messages des médias sociaux, les transactions de commerce électronique, les lectures de capteurs, etc. Les plates-formes de programmation de Big Data telles que Storm, Spark Streaming et S4 sont des systèmes de traitement de flux.
Traitement par lots vs. Traitement des flux: graphique de comparaison

Résumé du traitement par lots vs. Traitement des cours d'eau
Alors que les systèmes de traitement par lots sont nettement moins complexes et plus sophistiqués par rapport aux systèmes de traitement des flux, le coût des systèmes de traitement par lots peut sembler moins possible pour certaines entreprises et organisations qui n'ont pas de matériel coûteux pour commencer par. Cependant, les systèmes de traitement de flux peuvent être utilisés dans des applications qui nécessitent une production continue à partir de données entrantes en temps réel telles que les applications de médias sociaux, le marché boursier, etc. Bien que le traitement du flux fonctionne mieux pour les cas d'utilisation de l'entreprise où le temps est une contrainte, le traitement par lots fonctionne bien lorsque tous les liés ont été pré-stockés. Donc, tout se résume à votre cas d'utilisation de l'entreprise.
- « Différence entre l'exploration de données supervisée et sans surveillance
- Différence entre le panier et la carte mère »