

Différence entre les mégadonnées et Hadoop

- 2986
- 872
- Sarah Poirier
La relation entre les mégadonnées et Hadoop est l'un des sujets importants d'intérêt parmi les débutants. Et la distinction entre ces deux concepts connexes est plutôt fascinant. Les mégadonnées sont un atout précieux qui, sans son gestionnaire, n'est pas une utilisation particulière. Donc, Hadoop est le gestionnaire qui apporte la meilleure valeur de l'actif. Jetons un coup d'œil sur les deux suivis des différences entre les deux.
Qu'est-ce qu'un Big Data?
Dans le monde numérique d'aujourd'hui, nous sommes entourés d'une majeure partie de données. Il suffirait de dire que les données sont partout. L'évolution rapide d'Internet et de l'Internet des appareils (IoT) et l'utilisation continue des médias électroniques ont conduit à la naissance du commerce électronique et des médias sociaux. En conséquence, une quantité massive de données a été générée et, en fait, générant toujours quotidiennement. Cependant, les données n'ont aucune utilité à moins que vous ayez l'ensemble de compétences nécessaires pour les analyser. Les données dans sa forme actuelle sont des données brutes, dont la plupart sont du contenu généré par l'utilisateur, qui doit être analysé et stocké. Les données sont générées à partir de plusieurs sources, des médias sociaux aux systèmes intégrés / sensoriels, des journaux de machines, des sites de commerce électronique, etc. Le traitement d'une telle quantité de données est difficile. Big Data est un terme parapluie qui fait référence aux nombreuses façons de gérer systématiquement les données et de traiter à une si grande échelle. Les mégadonnées se réfèrent à de grands ensembles de données complexes qui sont trop compliqués pour être analysés par des applications traditionnelles de traitement des données.
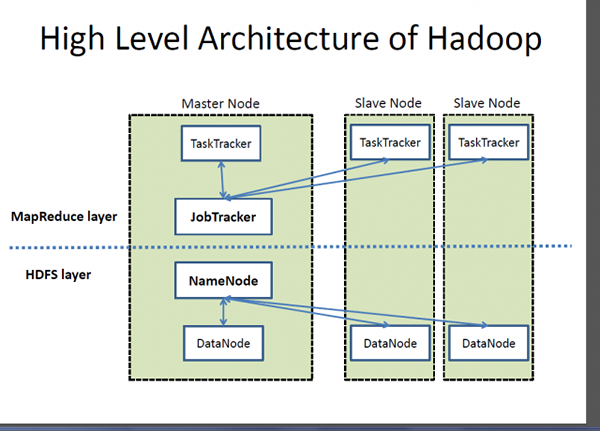
Qu'est-ce qu'un Hadoop?
Si Big Data est un atout très précieux, Hadoop est un programme ou un outil pour faire ressortir la meilleure valeur de cet actif. Hadoop est un programme d'utilité logicielle open source développé pour gérer le problème du stockage et du traitement de grands ensembles de données complexes. Apache Hadoop est probablement l'un des cadres logiciels les plus populaires et les plus utilisés utilisés pour stocker et traiter les mégadonnées. Il s'agit d'un modèle de programmation simplifié qui vous permet d'écrire et de vérifier facilement les systèmes distribués et sa distribution économique automatique des connaissances sur une marchandise de serveurs en grappe. Ce qui rend Hadoop distinctif, c'est sa capacité à passer d'un seul serveur à des milliers de machines de serveur de matières premières. En termes simples, Apache Hadoop est le cadre logiciel de facto pour stocker et traiter une énorme quantité de données, ce qui est souvent appelé Big Data. Deux composants clés de l'écosystème Hadoop sont le système de fichiers distribué Hadoop (HDFS) et le modèle de programmation MapReduce.
Différence entre les mégadonnées et Hadoop
Bases
- Big Data et Hadoop sont les deux termes les plus familiers étroitement liés les uns aux autres d'une manière que sans Hadoop, les mégadonnées n'auraient aucune signification ni valeur. Considérez les mégadonnées comme un actif de valeur profonde, mais pour apporter une certaine valeur de cet actif, vous avez besoin d'un moyen. Ainsi, Apache Hadoop est un programme d'utilité conçu pour provoquer la meilleure valeur des mégadonnées. Les mégadonnées se réfèrent à de grands ensembles de données complexes qui sont trop compliqués pour être analysés par des applications traditionnelles de traitement des données. Apache Hadoop est un cadre logiciel utilisé pour gérer le problème du stockage et du traitement de grands ensembles de données complexes.
Concept
- Les données dans sa forme brute ne sont pas utiles et très difficiles à travailler à moins que vous ne convertiez cette entité brute appelée données en informations. Nous sommes entourés de tonnes de tonnes de données que nous voyons et utilisons dans cette ère numérique. Par exemple, nous avons tellement de contenu sur les sites et les applications de médias sociaux tels que Twitter, Instagram, YouTube, etc. Ainsi, le Big Data fait référence à ces énormes quantités de données structurées et non structurées et les informations que nous pouvons obtenir de ces données, telles que des modèles, des tendances ou tout ce qui contribuerait à rendre ces données beaucoup plus faciles à travailler avec. Hadoop est un cadre logiciel distribué qui gère le stockage et le traitement de ces grands ensembles de données sur une marchandise de serveurs en grappe.
But
- Les données dans sa forme actuelle sont des données brutes, dont la plupart sont du contenu généré par l'utilisateur, qui doit être analysé et stocké. Les ensembles de données augmentent à un rythme exponentiel et ils deviennent incontrôlables. Nous avons donc besoin de moyens de gérer toutes ces données structurées et non structurées et nous avons besoin d'un modèle de programmation simple qui fournira les bonnes solutions au monde du Big Data. Cela nécessite un modèle de calcul à grande échelle par opposition aux modèles de calcul traditionnels. Apache Hadoop est un système distribué qui permet à la distribution de calcul sur plusieurs machines au lieu d'utiliser une seule machine. Il est conçu pour distribuer et traiter une énorme quantité de données sur les nœuds du cluster.
Big Data vs. Hadoop: tableau de comparaison
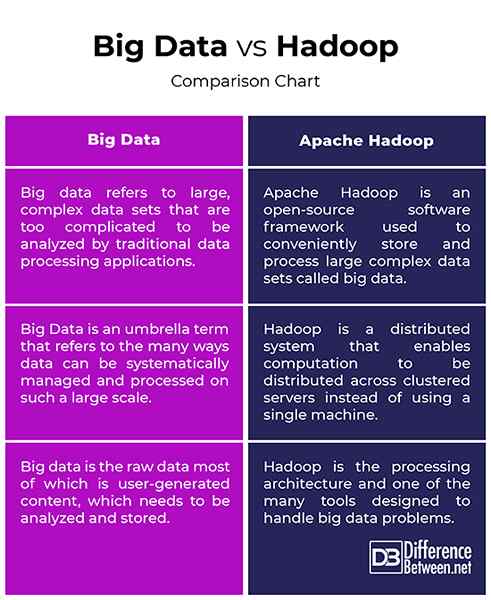
Résumé des mégadonnées vs. Hadoop
Le Big Data est un atout très précieux qui n'est pas utile à moins que nous ne trouvions des moyens de travailler dessus. Des applications de médias sociaux telles que Twitter, Facebook, Instagram, YouTube, etc. sont les exemples de la vie réelle de Big Data qui pose des défis aux technologies que nous utilisons ces jours-ci. Ces données en croissance rapide avec du contenu non structuré sont communément appelées Big Data. Mais, les données dans sa forme brute sont très difficiles à travailler avec. Nous avons besoin de moyens d'acquérir, de stocker, de traiter et d'analyser ces données afin que nous puissions en tirer quelque chose d'utile, comme un modèle ou une tendance. Hadoop est cet outil qui aide à stocker et à traiter ces ensembles de données complexes qui sont trop grands pour être gérés à l'aide de techniques et d'outils de calcul traditionnels.