

Différence entre le clustering et la classification
- 2478
- 403
- M Lilou Philippe
Les techniques de clustering et de classification sont utilisées dans l'apprentissage automatique, la récupération des informations, l'enquête d'image et les tâches connexes.
Ces deux stratégies sont les deux principales divisions des processus d'exploration de données. Dans le monde de l'analyse des données, ceux-ci sont essentiels pour gérer les algorithmes. Plus précisément, ces deux processus divisent les données en ensembles. Cette tâche est très pertinente à l'ère de l'information d'aujourd'hui, car l'immense augmentation des données associées au développement doit être facilitée.
Notamment, le regroupement et la classification aident à résoudre des problèmes mondiaux tels que la criminalité, la pauvreté et les maladies grâce à la science des données.
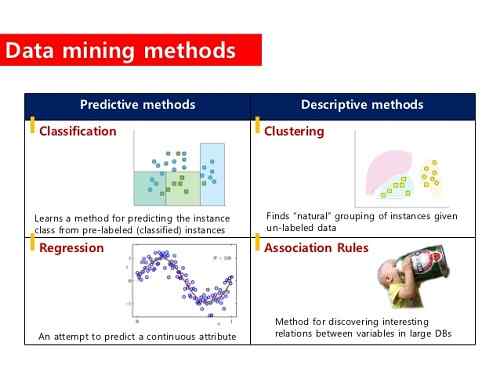
Qu'est-ce que le regroupement?
Fondamentalement, le regroupement implique le regroupement des données concernant leurs similitudes. Il concerne principalement les mesures de distance et les algorithmes de clustering qui calculent la différence entre les données et les divisent systématiquement.
Par exemple, les élèves avec des styles d'apprentissage similaires sont regroupés et sont enseignés séparément de ceux qui ont des approches d'apprentissage différentes. Dans l'exploration de données, le clustering est le plus souvent appelé «technique d'apprentissage non supervisé» car le regroupement est basé sur une caractéristique naturelle ou inhérente.
Il est appliqué dans plusieurs domaines scientifiques tels que les technologies de l'information, la biologie, la criminologie et la médecine.
Caractéristiques du clustering:
- Aucune définition exacte
Le clustering n'a pas de définition précise, c'est pourquoi il existe différents algorithmes de clustering ou modèles de cluster. En gros, les deux types de regroupement sont durs et doux. Le clustering dur concerne l'étiquetage d'un objet comme appartenant simplement à un cluster ou non. En revanche, le regroupement doux ou le clustering flou spécifie le degré de la façon dont quelque chose appartient à un certain groupe.
- Difficile à évaluer
La validation ou l'évaluation des résultats de l'analyse du regroupement est souvent difficile à déterminer en raison de son inexactitude inhérente.
- Sans surveillance
Comme il s'agit d'une stratégie d'apprentissage non supervisée, l'analyse est simplement basée sur les caractéristiques actuelles; Ainsi, aucune réglementation stricte n'est nécessaire.
Qu'est-ce que la classification?
La classification consiste à attribuer des étiquettes aux situations ou classes existantes; Par conséquent, le terme «classification». Par exemple, les élèves présentant certaines caractéristiques d'apprentissage sont classés comme apprenants visuels.
La classification est également connue sous le nom de «Technic d'apprentissage supervisé» dans lequel les machines apprennent des données déjà étiquetées ou classifiées. Il est très applicable dans la reconnaissance des modèles, les statistiques et la biométrie.
Caractéristiques de la classification
- Utilise un «classificateur»
Pour analyser les données, un classificateur est un algorithme défini qui mappe concrètement une information à une classe spécifique. Par exemple, un algorithme de classification formerait un modèle pour identifier si une certaine cellule est maligne ou bénigne.
- Évalué par des mesures communes
La qualité d'une analyse de classification est souvent évaluée via la précision et le rappel qui sont des procédures métriques populaires. Un classificateur est évalué en ce qui concerne sa précision et sa sensibilité à l'identification de la sortie.
- Supervisé
La classification est une technique d'apprentissage supervisée car elle attribue des identités précédemment déterminées basées sur des fonctionnalités comparables. Il déduit une fonction d'un ensemble de formation étiqueté.
Différences entre le regroupement et la classification
- Surveillance
La principale différence est que le clustering n'est pas supervisé et est considéré comme «auto-apprentissage» tandis que la classification est supervisée car elle dépend des étiquettes prédéfinies.
- Utilisation de l'ensemble de formation
Le regroupement n'utilise pas de manière poignante des ensembles de formation, qui sont des groupes d'instances utilisées pour générer les groupements, tandis que la classification a impérativement besoin d'ensembles de formation pour identifier les fonctionnalités similaires.
- Étiquetage
Le clustering fonctionne avec des données non marquées car elle n'a pas besoin de formation. D'un autre côté, la classification traite à la fois des données non marquées et étiquetées dans ses processus.
- But
Les groupes de regroupement des objets dans le but de restreindre les relations ainsi que d'apprendre de nouvelles informations à partir de modèles cachés tandis que la classification cherche à déterminer quel groupe explicite un certain objet appartient.
- Détails
Bien que la classification ne spécifie pas ce qui doit être appris, le clustering spécifie l'amélioration requise car elle souligne les différences en considérant les similitudes entre les données.
- Phases
Généralement, le clustering ne se compose qu'une seule phase (regroupement) tandis que la classification a deux étapes, la formation (modèle apprend de l'ensemble de données de formation) et les tests (classe cible est prévu).
- Conditions aux limites
La détermination des conditions aux limites est très importante dans le processus de classification par rapport au regroupement. Par exemple, savoir que la plage de pourcentage de «faible» par rapport à «modérée» et «élevée» est nécessaire pour établir la classification.
- Prédiction
Par rapport au clustering, la classification est plus impliquée dans la prédiction car elle vise particulièrement à identifier les classes cibles. Par exemple, cela peut être appliqué dans la «détection des points clés faciaux» car il peut être utilisé pour prédire si un certain témoin mente ou non.
- Complexité
Étant donné que la classification comprend plus d'étapes, traite de la prédiction et implique des diplômes ou des niveaux, sa «nature est plus compliquée par rapport au regroupement qui concerne principalement le regroupement des attributs similaires.
- Nombre d'algorithmes probables
Les algorithmes de clustering sont principalement linéaires et non linéaires tandis que la classification consiste en plus d'outils algorithmiques tels que les classificateurs linéaires, les réseaux de neurones, l'estimation du noyau, les arbres de décision et les machines à vecteurs de support.
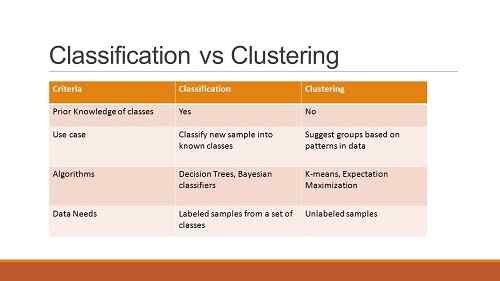
Clustering vs Classification: Tableau comparant la différence entre le clustering et la classification
| Regroupement | Classification |
| Données non supervisées | Données supervisées |
| N'apprécie pas beaucoup les ensembles de formation | Prévaluait beaucoup les ensembles de formation |
| Fonctionne uniquement avec des données non marquées | Implique à la fois des données non marquées et étiquetées |
| Vise à identifier les similitudes entre les données | Vise à vérifier où appartient une donnée à |
| Spécifie le changement requis | Ne spécifie pas l'amélioration requise |
| A une seule phase | A deux phases |
| Déterminer les conditions aux limites n'est pas primordiale | L'identification des conditions aux limites est essentielle pour exécuter les phases |
| Ne traite généralement pas de prédiction | Traite de la prédiction |
| Emploie principalement deux algorithmes | A un certain nombre d'algorithmes probables à utiliser |
| Le processus est moins complexe | Le processus est plus complexe |
Résumé sur le regroupement et la classification
- Les analyses de regroupement et de classification sont fortement utilisées dans les processus d'exploration de données.
- Ces techniques sont appliquées dans une myriade de sciences qui sont essentielles pour résoudre les problèmes mondiaux.
- Surtout, le regroupement traite des données non supervisées; Ainsi, sans étiquette tandis que la classification fonctionne avec des données supervisées; Ainsi, étiqueté. C'est l'une des principales raisons pour lesquelles le regroupement n'a pas besoin d'ensembles de formation alors que la classification.
- Il existe plus d'algorithmes associés à la classification par rapport au clustering.
- Le clustering cherche à vérifier comment les données sont similaires ou différentes entre elles tandis que la classification se concentre sur la détermination des «classes» ou des groupes de données. Cela rend le processus de clustering plus axé sur les conditions aux limites et l'analyse de classification plus compliquée dans le sens où elle implique plus d'étapes.