

Différence entre l'annotation des données et l'étiquetage
- 2711
- 190
- Théo Roy
Depuis des années, les entreprises investissent massivement dans l'apprentissage automatique. En fait, l'apprentissage automatique est l'un des domaines de recherche les plus actifs dans le domaine de l'intelligence artificielle (IA). Le principal objectif de la recherche dans le domaine de l'apprentissage automatique est de créer des machines ou des ordinateurs intelligents et conscients de soi capables de reproduire les compétences cognitives humaines et d'acquérir des connaissances par eux-mêmes. Ainsi, comprendre l'apprentissage humain suffisamment bien pour reproduire les aspects de ce comportement d'apprentissage dans les machines est un digne scientifique en soi. Chaque jour, les humains enseignent aux ordinateurs pour résoudre de nombreux problèmes nouveaux et passionnants, tels que jouer votre liste de lecture préférée, montrant les itinéraires vers votre restaurant le plus proche, etc.
Mais il y a encore tellement de choses que les ordinateurs ne peuvent pas faire, en particulier dans le contexte de la compréhension du comportement humain. Les méthodes statistiques se sont avérées être un moyen efficace pour aborder ces problèmes, mais les techniques d'apprentissage automatique fonctionnent mieux lorsque les algorithmes sont fournis avec des indications sur ce qui est pertinent et significatif dans un ensemble de données, plutôt que d'énormes pales de données. Dans le contexte du traitement du langage naturel, ces pointeurs se présentent souvent sous forme d'annotations - l'art d'étiqueter les données disponibles dans différents formats. L'annotation et l'étiquetage des données sont deux éléments fondamentaux de l'apprentissage automatique qui aident les machines à reconnaître les images, le texte et les vidéos.
Qu'est-ce que l'annotation des données?
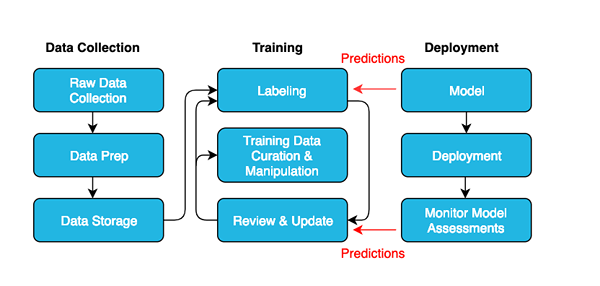
Fournir simplement un ordinateur avec des quantités massives de données et s'attendre à ce qu'elle apprend à parler ne suffit pas. Les données doivent être collectées et présentées de telle manière qu'un ordinateur peut facilement reconnaître les modèles et les inférences des données. Cela se fait généralement en ajoutant des métadonnées pertinentes à un ensemble de données. Toute étiquette de métadonnées utilisée pour marquer les éléments de l'ensemble de données est appelée annotation sur l'entrée. Ainsi, dans l'apprentissage automatique, les données doivent être annotées ou pour dire simplement étiquetées, afin que le système puisse facilement le reconnaître. Mais, pour que les algorithmes apprennent efficacement et efficacement, l'annotation sur les données doit être précise et pertinente pour le travail dont l'ordinateur est chargé. En termes simples, l'annotation des données est la technique de l'étiquetage des données afin que la machine puisse comprendre et mémoriser les données d'entrée.
Qu'est-ce que l'étiquetage des données?
Les données se présentent sous de nombreuses formes différentes telles que le texte, les images, l'audio et la vidéo. Pour enrichir les données afin que la machine puisse la reconnaître à travers des algorithmes d'apprentissage automatique, les données doivent être étiquetées. L'étiquetage des données, comme son nom l'indique, est le processus d'identification des données brutes afin d'attacher le sens à différents types de données afin de former un modèle d'apprentissage automatique. Lorsque les données sont étiquetées, il est utilisé pour la formation d'algorithmes avancés pour reconnaître les modèles à l'avenir. L'étiquetage consiste essentiellement à marquer les données ou à ajouter des métadonnées pour la rendre plus significative et informative afin que les machines puissent les comprendre et en apprendre. Par exemple, une étiquette peut indiquer qu'une image contient une personne ou un animal, ou un fichier audio se trouve dans quelle langue, ou pour déterminer le type d'action effectuée dans une vidéo.
Différence entre l'annotation des données et l'étiquetage
Signification
- L'étiquetage des données et l'annotation sont les termes souvent utilisés de manière interchangeable pour représenter le processus de marquage ou d'étiquetage des données disponibles dans de nombreux formats différents. L'annotation des données est essentiellement la technique d'étiquetage des données afin que la machine puisse comprendre et mémoriser les données d'entrée à l'aide d'algorithmes d'apprentissage automatique. L'étiquetage des données, également appelé étiquetage de données, signifie attacher un sens à différents types de données afin de former un modèle d'apprentissage automatique. L'étiquetage identifie une seule entité à partir d'un ensemble de données.
But
- L'étiquetage est une pierre angulaire de l'apprentissage automatique supervisé et diverses industries comptent encore fortement annoter manuellement et étiqueter leurs données. Les étiquettes sont utilisées pour identifier les fonctionnalités de l'ensemble de données pour les algorithmes NLP tandis que l'annotation des données peut être utilisée pour les modèles de perception basés sur des visuels. L'étiquetage est plus compliqué que l'annotation. L'annotation aide à reconnaître les données pertinentes via la vision par ordinateur tandis que l'étiquetage est utilisé pour la formation d'algorithmes avancés pour reconnaître les modèles à l'avenir. Les deux processus doivent être effectués avec une précision absolue pour s'assurer que quelque chose de significatif sort des données afin de développer un modèle d'IA basé sur la PNL.
Applications
- L'annotation des données est un élément fondamental pour créer des données de formation pour la vision par ordinateur. Des données annotées sont nécessaires pour former des algorithmes d'apprentissage automatique pour voir le monde comme nous les humains le voyons. L'idée est de rendre les machines assez intelligentes pour apprendre, agir et se comporter comme des humains, mais d'où vient cette intelligence? La réponse est les données et beaucoup, beaucoup d'entre elles. L'annotation est un processus utilisé dans l'apprentissage automatique supervisé pour la formation des ensembles de données pour aider les machines à comprendre et à reconnaître les données d'entrée et à agir en conséquence. L'étiquetage est utilisé pour identifier les caractéristiques clés présentes dans les données tout en minimisant l'implication humaine. Les cas d'utilisation du monde réel incluent la PNL, le traitement audio et vidéo, les visions informatiques, etc.
Annotation des données vs. Étiquetage des données: graphique de comparaison

Résumé
L'annotation est un processus utilisé dans l'apprentissage automatique supervisé pour la formation des ensembles de données pour aider les machines à comprendre et à reconnaître les données d'entrée et à agir en conséquence. L'étiquetage est utilisé pour identifier les caractéristiques clés présentes dans les données tout en minimisant l'implication humaine. L'étiquetage est une pierre angulaire de l'apprentissage automatique supervisé et diverses industries comptent encore fortement annoter manuellement et étiqueter leurs données. Parce que le mauvais étiquetage peut conduire à une IA compromise, l'étiquetage ou l'annoting doit être effectué avec précision afin qu'ils puissent être utilisés pour les applications d'IA.