

Différence entre l'exploration de données et les mégadonnées

- 2140
- 477
- Lena Muller
Nous vivons dans un monde où des quantités folles de données sont collectées quotidiennement. Par exemple, environ 48 heures de vidéos sont téléchargées sur YouTube chaque minute. Mais ce n'est pas la quantité de données qui compte; C'est ce que les organisations et les entreprises font avec les données qui comptent. Stocker et traiter les données devient une tâche difficile, car les données se développent rapidement. Du point de vue des entreprises, les données sont roi. Et l'analyse est la nouvelle «reine des sciences.«L'exploration de données est un outil pour découvrir les connaissances des données.
Qu'est-ce que le Big Data?
Les mégadonnées signifiaient auparavant des morceaux non structurés de données extraites ou générées à partir d'Internet à l'échelle des pétaoctets. En fait, le terme «big data» dans sa forme actuelle semble avoir été utilisé pour la première fois à la fin des années 1990 et le premier journal académique a été publié en 2003 par Francis X. Diebolt - «Modèles de facteurs dynamiques de Big Data pour la mesure et les prévisions macroéconomiques.«L'ère du Big Data est reconnue par des volumes de données en expansion rapide, bien au-delà de ce que la plupart des gens imaginaient se produire. Avant le début de l'ère du Big Data, les organisations ont attribué une valeur relativement faible aux données. Mais avec l'explosion des données, cet investissement dans la collecte et le stockage de données pour sa valeur future potentielle a changé. Actuellement, 90% des mégadonnées sont connues pour s'être accumulées au cours des deux dernières années seulement. De nombreuses innovations technologiques et l'utilisation croissante des smartphones entraînent une augmentation spectaculaire des données. Donc, tout simplement, les mégadonnées reflètent le monde en évolution rapide dans laquelle nous vivons.

Qu'est-ce que l'exploration de données?
Maintenant que nous sommes à l'ère du Big Data, le plus grand défi n'est pas d'obtenir des données mais d'obtenir les bonnes données et d'utiliser des ordinateurs pour augmenter nos connaissances et identifier les modèles que nous ne pouvions pas identifier auparavant. Les données sous sa forme brute n'ont aucune valeur. Le taux d'accumulation de données augmente plus rapidement que notre capacité à analyser et à traiter de tels ensembles de données importants afin de prendre des décisions. Les téraoctets ou les pétaoctets de données versent dans nos réseaux informatiques chaque seconde. Des outils puissants et polyvalents sont nécessaires pour filtrer automatiquement à travers les énormes quantités de données et découvrir des informations précieuses, et enfin transformer ces données en connaissances organisées. Cette nécessité a conduit à la naissance de l'exploration de données. Ainsi, l'exploration de données transforme les données en connaissances. L'exploration de données tente de trouver des relations et des associations entre les éléments de données qui ne sont pas trouvés auparavant. C'est le processus de recherche de modèles, d'anomalies et de corrélations dans les grandes réserves de données et de transformer ces données en connaissances exploitables.
Différence entre l'exploration de données et les mégadonnées
Définition
- Big Data est un terme tout compris qui fait référence à la collecte et à l'analyse ultérieure d'ensembles de données significativement importants qui peuvent contenir des informations ou des informations cachées qui n'ont pas pu être découvertes à l'aide de méthodes et d'outils traditionnels. La quantité de données est beaucoup pour les systèmes informatiques traditionnels pour gérer et analyser.
L'exploration de données est le processus de déplacement à travers les piles massives de données pour des informations et des informations exploitables. C'est le processus de recherche de modèles, d'anomalies et de corrélations dans les grandes réserves de données et de transformer ces données brutes en connaissances organisées.
But
- Les mégadonnées se réfèrent à l'utilisation de l'analyse prédictive, de l'analyse du comportement des utilisateurs ou d'autres méthodes d'analyse de données pour extraire la valeur des données avec des tailles au-delà de la capacité des outils logiciels couramment utilisés pour capturer, gérer et traiter. Le but est de découvrir les informations des ensembles de données diverses, complexes et à grande échelle.
L'exploration de données tente de trouver des relations et des associations entre les éléments de données qui ne sont pas trouvés auparavant. L'exploration de données est l'extraction des connaissances et comment utiliser les données brutes pour générer une sorte de connaissances qui peuvent être utilisées pour la prise de décision. Il tente de trouver des motives cachées à partir de données déjà disponibles.
Caractéristiques
- Les mégadonnées peuvent être définies par les trois principaux attributs ou caractéristiques, les trois vs: variété, volume et vitesse. Ceux-ci sont essentiels pour comprendre comment nous pouvons mesurer les mégadonnées. La variété fait référence aux différents types de données, tels que des données structurées, semi-structurées et non structurées; Le volume fait référence aux quantités massives de données générées; et la vitesse fait référence à la vitesse à laquelle les données sont générées.
L'exploration de données est similaire à la recherche, mais elle ne recherche ni ne demande les données; Il est appliqué sur diverses formes de données pour trouver les modèles intéressants plutôt que sur les résultats de la base de données.
Cas d'utilisation
- Divers champs de la vie quotidienne d'aujourd'hui utilisent les mégadonnées pour faciliter le processus de stockage et de traitement des données. Les nombreux exemples de cas d'utilisation des mégadonnées comprennent les services financiers, les compagnies aériennes et les entreprises de camionnage, le secteur des soins de santé, les télécommunications et les services publics, les médias et le divertissement, le commerce électronique, l'éducation, l'IoT, etc.
Les applications de l'exploration de données sont sages et diverses. Certaines applications de base incluent des recommandations de produits dans le commerce électronique, l'analyse des pages Web, les prévisions boursières, l'exploration de données sur les soins de santé, etc. L'exploration de données est une base de l'apprentissage automatique et des applications d'IA dans le monde entier.
Exploration de données vs. Big Data: Tableau de comparaison
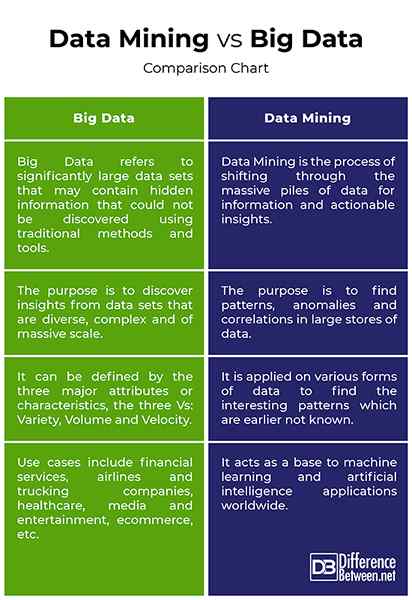
Résumé de l'exploration de données et des mégadonnées
Les mégadonnées se réfèrent aux grands ensembles de données qui peuvent contenir des informations ou des informations cachées qui ne peuvent pas être découvertes à l'aide de méthodes et d'outils traditionnels. La quantité de données est beaucoup pour les systèmes informatiques traditionnels pour gérer et analyser. L'exploration de données transforme les données brutes en connaissances car les données sous sa forme brute n'ont aucune valeur. L'exploration de données tente de trouver des relations et des associations entre les éléments de données qui peuvent être utilisés pour prendre une prise de décision efficace.
- « Différence entre le risque inhérent et le risque de contrôle
- Différence entre le wireframe et le prototype »