

Différence entre Elasticsearch et Hadoop
- 2208
- 326
- Mlle Lina Schmitt
Elasticsearch est un moteur de recherche évolutif et axé sur les documents construit autour de Lucene pour faciliter tous les types de recherche (y compris la recherche en texte intégral) et l'analyse. En plus d'être un moteur de recherche, Elasticsearch est une boutique de documents multi-locataires distribuée. Hadoop est un cadre distribué qui permet de stocker et de traiter les mégadonnées dans un environnement distribué à travers des grappes d'ordinateurs à l'aide de modèles de programmation simples.
Qu'est-ce que Elasticsearch?
Elasticsearch est un moteur de recherche et analytique de texte complet hautement échecable et distribué qui vous permet de stocker, de rechercher et d'analyser de grands volumes de données en temps quasi réel. Bien qu'il ait commencé comme un moteur de recherche en texte intégral, il commence à évoluer comme un moteur analytique, qui peut prendre en charge des agrégations complexes. Il est construit au-dessus de Lucene, une bibliothèque de logiciels de moteur de recherche entièrement écrite en Java et prise en charge par l'Apache Software Foundation. Apache Lucene est l'une des bibliothèques les plus utilisées pour la recherche. Elasticsearch est distribué de nature et est très facile à utiliser, ce qui facilite le démarrage et l'échelle car vous avez plus de données. Bien qu'il soit principalement utilisé comme moteur de recherche, il peut être utilisé comme cadre d'analyse via son puissant système d'agrégation et le stockage de données.
Qu'est-ce que Hadoop?
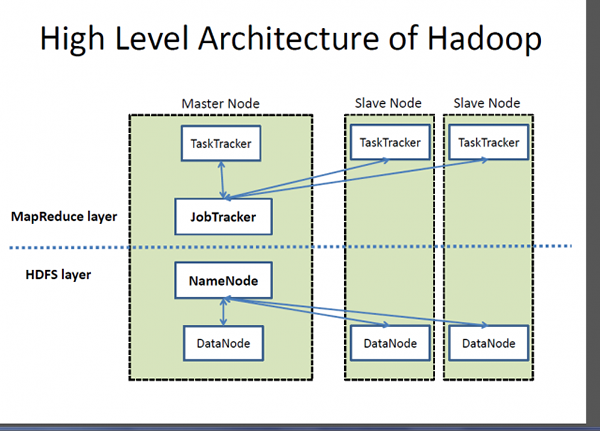
Hadoop est un cadre de traitement très évolutif et distribué pour gérer le traitement des données et le stockage de grands ensembles de données exécutés dans des systèmes en cluster. Hadoop est une collection de services publics de logiciels qui permet le stockage et le traitement des mégadonnées et les applications en cours d'exécution de grappes matérielles de marchandises. Hadoop est la marque déposée de l'Apache Software Foundation qui a commencé comme un projet logiciel unique pour prendre en charge un moteur de recherche Web mais a évolué en un écosystème d'outils et d'applications utilisés pour analyser un grand volume de données. Hadoop est basé sur le modèle de programmation MapReduce pour le traitement d'énormes ensembles de données sur des grappes de matériel de base. Le composant central de Hadoop est le système de fichiers distribué Hadoop (HDFS) qui est un système de fichiers parallèles haute performance conçu pour répondre aux besoins du traitement des mégadonnées, comme un accès en streaming à gros bloc.
Différence entre Elasticsearch et Hadoop
Outil
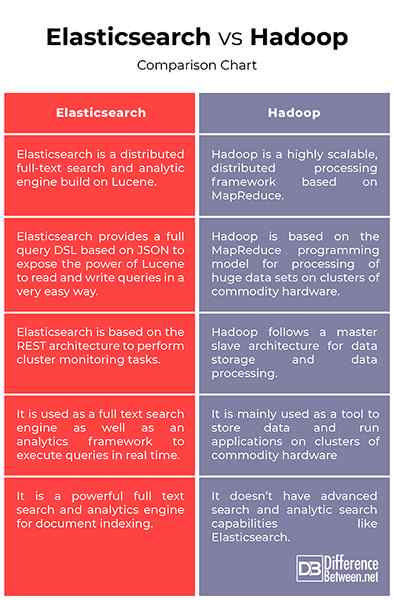
- Elasticsearch est un moteur de recherche et analytique de texte complet hautement échecable et distribué qui vous permet de stocker, de rechercher et d'analyser de grands volumes de données en temps quasi réel. Bien qu'il soit principalement utilisé comme moteur de recherche, il peut être utilisé comme cadre d'analyse via son puissant système d'agrégation et le stockage de données. Hadoop, en revanche, est un puissant cadre de traitement distribué qui a commencé comme un projet logiciel unique pour prendre en charge un moteur de recherche Web mais a évolué en un écosystème d'outils et d'applications utilisés pour analyser un grand volume de données.
Architecture
- Hadoop est un cadre logiciel open-source qui suit une architecture d'esclaves maître pour le stockage de données et le traitement des données à l'aide du système de programmation distribué Hadoop (HDFS) et du modèle de programmation MapReduce. HDFS est un système de fichiers parallèles haute performance conçu pour répondre aux besoins du traitement des mégadonnées. Elasticsearch, en revanche, est basé sur l'architecture REST et fournit des points de terminaison API pour effectuer des opérations CRUD sur HTTP ainsi que pour effectuer des tâches de surveillance des cluster. Cela vous permet d'intégrer, gérer et interroger les données indexées de plusieurs manières différentes.
Principe
- Elasticsearch fournit une requête complète DSL basée sur JSON pour exposer le pouvoir de Lucene pour lire et écrire des requêtes de manière très facile. La plupart des magasins de données NoSQL utilisent JSON pour stocker leurs données comme le format JSON est très concis, flexible et facile à comprendre. Hadoop, en revanche, est basé sur le modèle de programmation MapReduce pour le traitement d'énormes ensembles de données sur des grappes de matériel de marchandises. MapReduce est un paradigme de programmation dans le cadre Hadoop qui est utilisé pour accéder à de grandes quantités de données stockées sur des milliers de serveurs dans un cluster Hadoop.
Utiliser
- Elasticsearch est un moteur de recherche de texte intégral qui est son utilisation principale, mais il est également utilisé comme cadre d'analyse via son puissant système d'agrégation. Il peut également être utilisé comme un moteur analytique très puissant pour exécuter toutes les requêtes que vous exécuteriez généralement en lot ou hors ligne en temps réel. Il prend en charge non seulement la recherche mais aussi les agrégations complexes. Hadoop, en revanche, est principalement utilisé comme un outil pour stocker des données et exécuter des applications sur des grappes de matériel de base en utilisant le système de stockage le plus fiable au monde, HDFS.
Elasticsearch VS. Hadoop: tableau de comparaison
Résumé de Elasticsearch vs. Hadoop:
Elasticsearch est un outil puissant pour la recherche de texte intégral et l'indexation des documents au sommet de Lucene, une bibliothèque de logiciels de moteur de recherche entièrement écrite en Java, tandis que Hadoop est un cadre de traitement des données pour gérer de grands volumes de données en une fraction de secondes. Hadoop est basé sur le modèle de programmation MapReduce populaire pour le traitement d'énormes ensembles de données sur les grappes de matériel de base. Elasticsearch est un puissant moteur d'analyse pour gérer l'ensemble de votre pipeline d'analyse, tandis que Hadoop est un cadre pour gérer tout travail d'agrégation ou de transformation de données.
- « Différence entre les charges et le botox
- Différence entre la Garde nationale aérienne et la réserve de l'Air Force »