

Différence entre Hadoop et Cassandra
- 4176
- 565
- Juliette Lacroix
Avec des quantités massives de données qui sont générées à très grande vitesse par une explosion massive de l'Internet des objets et une utilisation croissante des médias sociaux, la capacité de stocker et d'analyser ces quantités massives de données a augmenté. Hadoop est l'un des outils sophistiqués conçu pour gérer de si grandes quantités de données, qui est souvent appelée Big Data. Cassandra est une autre base de données très évolutive qui est facile à déployer et à gérer. Mais ce qui est le meilleur choix - Hadoop ou Cassandra?
Qu'est-ce que Hadoop?
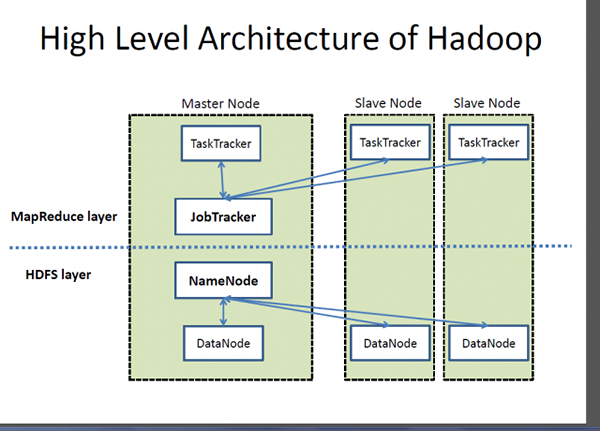
Apache Hadoop est le cadre de facto pour le traitement et le stockage de grands volumes de données, qui est souvent appelé «Big Data». Hadoop est la pierre angulaire de toutes les solutions de Big Data. Projet de la Fondation du logiciel Apache, Hadoop est un système de traitement distribué à grande échelle conçu pour distribuer et traiter de grandes quantités de données sur les nœuds du cluster. Il ne vise pas à remplacer les systèmes de base de données traditionnels; En fait, Hadoop facilite l'utilisation de bases de données relationnelles en accélérant les opérations liées aux grands ensembles de données. Hadoop est basé sur le célèbre modèle de programmation MapReduce adapté au traitement d'énormes ensembles de données, distribué à travers un groupe de nœuds, en parallèle. Le système de fichiers distribué Hadoop (HDFS) est le système de fichiers de stockage et de traitement des données pour Hadoop qui s'exécute sur le matériel de marchandise et offre un accès en difficulté en parallèle à de grandes quantités de données.
Qu'est-ce que Cassandra?
Apache Cassandra est une base de données open-source, entièrement distribuée et axée sur la colonne qui offre une évolutivité supérieure et une tolérance aux défauts aux bases de données maîtresses uniques traditionnelles. Cassandra est une base de données non relationnelle, également appelée base de données NOSQL qui fonde sa conception de distribution sur la dynamo d'Amazon et son modèle de données sur BigTable de Google - une base de données NOSQL haute performance construite sur les technologies de stockage Google propriétaires pour les grandes infrastructures de base de données de données. Il s'agit d'un système de gestion distribué conçu pour gérer de grandes quantités de données structurées sur des serveurs de matières premières. Comparé à d'autres bases de données distribuées populaires comme HBASE, Voldermort et Riak, Apache Cassandra propose une interface robuste et expressive pour la modélisation et l'interrogation des données. La meilleure partie de Cassandra est qu'elle est distribuée, ce qui signifie qu'il est capable de fonctionner sur plusieurs machines.
Différence entre Hadoop et Cassandra
Définition
- Hadoop est un cadre open-source Apache écrit en Java qui est conçu pour gérer de grandes quantités de données qui doivent être traitées à grande échelle lorsque vous traitez beaucoup de données en même temps de façon en streaming ou de manière par lots. Apache Cassandra, en revanche, est une base de données hautement évolutive et entièrement distribuée conçue pour gérer de grandes quantités de données structurées sur des serveurs de produits. Apache Cassandra propose une interface robuste et expressive pour la modélisation et l'interrogation des données.
Déploiement
- Hadoop est un cadre évolutif conçu pour être déployé sur du matériel à faible coût. Le stockage HDFS est réparti sur un groupe de nœuds; Un seul grand fichier pourrait être stocké sur plusieurs nœuds du cluster. Il est déployé dans un seul centre de données, mais ils sont tous colocalisés géographiquement les uns avec les autres. Cassandra, en revanche, est déployé de manière très distribuée comme un groupe d'instances qui sont toutes conscientes les unes des autres. Les données peuvent être lues ou écrites sur n'importe quelle instance du cluster, appelé nœud, qui transmettra la demande à l'instance où les données appartiennent.
Cadre
- Apache Hadoop est un cadre de traitement du Big Data basé sur le célèbre modèle de programmation MapReduce adapté au traitement d'énormes ensembles de données, distribué sur un groupe de nœuds, en parallèle. Il s'agit d'un système de traitement distribué conçu pour distribuer et traiter de grandes quantités de données sur les nœuds du cluster. Cassandra, en revanche, est une base de données NOSQL entièrement distribuée qui offre une interface unique et expressive pour la modélisation et l'interrogation des données. Ce n'est pas comme les systèmes de base de données traditionnels; En fait, il stocke les données dans la paire de valeurs clés. Contrairement à Hadoop, Cassandra est principalement utilisée pour le traitement des données en temps réel.
Format de données
- Hadoop peut travailler avec n'importe quel type de données dans une variété de formats, qu'il soit structuré, semi-structuré ou non structuré, et tout ce que vous pouvez penser - images, JSON, XML, etc. Cassandra, en revanche, est un système de gestion distribué conçu pour gérer de grandes quantités de données structurées sur des serveurs de matières premières. En plus, Cassandra ne prend pas en charge les images.
Architecture
- Hadoop suit une architecture esclave maître composée de nœuds maîtres et de nœuds esclaves. Le namemode est le nœud maître et les datanodes sont les nœuds esclaves. Habituellement, un démon Datanode s'exécute sur chaque mode esclave et gère le stockage attaché à chaque Datanode. Le HDFS peut être déployé sur une large gamme de machines exécutant Java. Cassandra, en revanche, stocke les données sur différents nœuds avec un système distribué entre pairs, ce qui facilite le fonctionnement et le maintien d'un magasin décentralisé qu'un magasin maître / esclave car tous les nœuds sont les mêmes.
Hadoop VS. Cassandra: Tableau de comparaison

Résumé
Hadoop est la pierre angulaire des solutions de Big Data qui propose une plate-forme de pointe pour stocker et analyser des quantités massives d'ensembles de données et améliorer les systèmes de gestion de la base de données relationnels traditionnels. Apache Hadoop fournit un cadre distribué tolérant aux pannes pour le stockage et le traitement de très grands ensembles de données sur des grappes de produits. Cassandra est la principale base de données NOSQL qui prend les meilleures avancées technologiques des articles Dynamo et BigTable pour gérer de grandes quantités de données structurées sur les serveurs de produits. De plus, Cassandra est idéale pour les transactions en ligne rapides tandis que Hadoop est idéal pour un stockage et une récupération plus rapides des données.