

Différence entre Hadoop et MongoDB
- 4931
- 1333
- Théo Roy
Nous entendons le terme Big Data depuis un certain temps maintenant, mais qu'est-ce que ce Big Data? La quantité de données produites par l'Internet des objets a considérablement augmenté au fil des ans et elle continue d'augmenter à un rythme exponentiel. Le traitement de ces volumes massifs de données non adaptés aux méthodes traditionnelles à gérer est appelée Big Data. Ce type de données pose des défis aux systèmes de RDBM traditionnels utilisés pour stocker et traiter les données. La puissance de traitement nécessaire pour stocker et traiter autant de données en temps opportun et rentable est massive. Afin de résoudre ce problème, des solutions de mégadonnées nouvelles et améliorées sont nécessaires qui sont spécialement conçues pour le traitement de grandes données non structurées. Parmi les nombreuses technologies, Hadoop et MongoDB sont les deux choix populaires en ce qui concerne le stockage et le traitement des mégadonnées. Bien que les deux soient assez similaires dans ce qu'ils font, mais leur approche de la façon dont ils le font est très différente. Laisser un coup d'œil.
Qu'est-ce que MongoDB?
MongoDB est une base de données de documents open source qui est devenue la base de données de facto NoSQL avec des millions d'utilisateurs, des petites startups à la Fortune 500 entreprises. Les principales entreprises et sociétés informatiques de consommation tirent parti des capacités de MongoDB dans leurs produits et solutions. Écrit en C ++, MongoDB est une base de données multiplateforme orientée vers le document qui aborde efficacement les limites des bases de données basées sur le schéma SQL en fournissant des performances élevées, une haute disponibilité et des solutions d'évolutivité faciles. C'est une base de données conçue pour le Web moderne. Comme les autres bases de données NoSQL, MongoDB ne respecte pas les principes des SGBDR sans concepts de tables, de lignes et de colonnes. Il stocke ses données dans des documents BSON où toutes les données connexes sont placées ensemble dans un seul document.
Qu'est-ce que Hadoop?
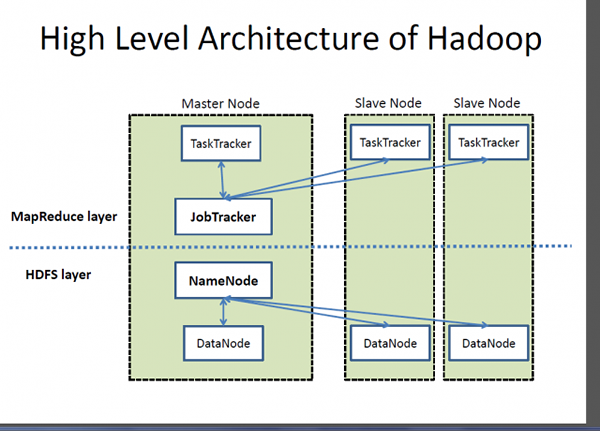
Hadoop est un cadre open source conçu pour le stockage et le traitement des volumes massifs de données sur des grappes d'ordinateurs. Il s'agit d'une application basée sur Java et une collection de différents logiciels qui crée un cadre de traitement des données. L'idée est de traiter les données à grande échelle à un coût raisonnable dans le moins de temps possible. Hadoop se compose de trois ressources primaires: le système de fichiers distribué Hadoop (HDFS), la plate-forme de programmation MapReduce de Google et l'ensemble de l'écosystème de Hadoop. L'écosystème Hadoop se compose de modules qui aident à programmer le système, à gérer et à configurer le cluster, à gérer et à stocker les données dans le cluster et à effectuer des tâches analytiques. Processus d'analyse des données Hadoop MapReduce AIDS. Hadoop est une marque déposée du logiciel Apache Foundaton et MapReduce est son cadre pour le traitement parallèle.
Différence entre Hadoop et MongoDB
Plateforme
- Bien que les deux soient considérés comme des solutions de Big Data, MongoDB est essentiellement une plate-forme à usage général conçu pour remplacer ou améliorer les systèmes SGBDR existants. MongoDB est une base de données de documents open source et l'une des principales bases de données NOSQL qui utilisent des documents, au lieu de lignes et de tables, pour la rendre flexible, évolutive et rapide. Hadoop, en revanche, est un cadre open source conçu pour le stockage et le traitement des volumes massifs de données sur des grappes d'ordinateurs. Hadoop n'est pas destiné à remplacer les systèmes SGBDR existants; En fait, il agit comme un supplément pour aider à l'analyse des données du processus de grands volumes de données structurées et non structurées.
Architecture
- L'écosystème Hadoop est une collection d'outils qui utilisent ou s'asseyent à côté de la plate-forme de programmation MapReduce de Google et HDFS (Système de fichiers distribué Hadoop) pour stocker et organiser des données, et gérer les machines qui exécutent Hadoop. HDFS est conçu pour l'accès aux données en streaming. MongoDB, en revanche, offre une approche différente; Il est basé sur l'architecture Nexus qui exploite les capacités de nosql tout en maintenant les bases des bases de données relationnelles. Il stocke les données sous forme de documents en représentation binaire appelée BSON (JSON binaire) où ils sont généralement organisés en tant que collections.
Force
- La plus grande force de Hadoop est MapReduce. Aujourd'hui, Hadoop est le meilleur cadre MapReduce du marché. Le concept derrière MapReduce est que l'entrée peut être divisée en morceaux logiques, où chaque morceau peut être traité indépendamment par une tâche de carte. Une tâche de carte peut s'exécuter sur n'importe quel nœud de calcul dans le cluster et plusieurs tâches de carte peuvent s'exécuter en parallèle sur le cluster. MongoDB, en revanche, est une base de données de documents qui peut gérer des charges allant des MVP et POC de démarrage aux applications d'entreprise avec des centaines de serveurs. MongoDB est passé de la solution de base de données de niche à la base de données de facto NoSQL. Sa notion de documents est vraiment expressive et flexible.
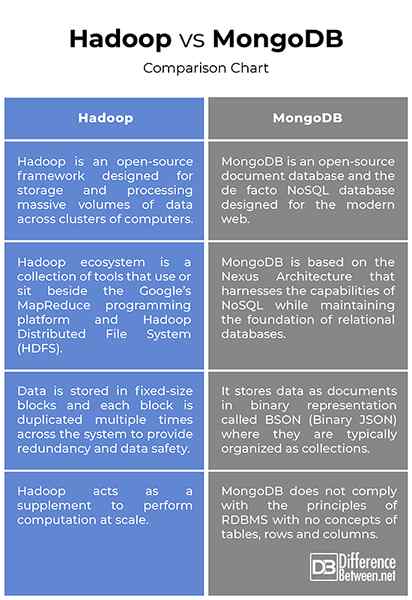
Hadoop VS. MongoDB: Tableau de comparaison
Résumé
Bien que les deux soient assez similaires dans ce qu'ils font, mais leur approche de la façon dont ils le font est très différente. MongoDB stocke les données comme documents en représentation binaire appelée BSON, tandis que dans Hadoop, les données sont stockées dans des blocs de taille fixe et chaque bloc est dupliqué plusieurs fois à travers le système. L'écosystème Hadoop est une collection d'outils qui utilisent ou s'assoient à côté de la plate-forme de programmation MapReduce de Google, tandis que MongoDB basé sur l'architecture Nexus qui exploite les capacités de Nosql tout en conservant les bases des bases de données relationnelles.