

Différence entre Hadoop et SQL
- 3680
- 976
- Carla Lefevre
Le terme «Big Data» est l'un des mots à la mode les plus chauds de l'ère numérique d'aujourd'hui. Chaque entreprise allant des petites startups aux grandes entreprises a de l'argent pour les mégadonnées. Soudain, nous constatons la convergence de tendances importantes qui transforment fondamentalement l'industrie et il y a une explosion de données en raison du nombre croissant d'appareils connectés à Internet. Big Data est exactement là où le cadre open source Hadoop arrive à l'image. Hadoop fournit un cadre pour stocker et récupérer d'énormes quantités de données à des fins de traitement et d'analyse. Mais comment Hadoop est différent des autres systèmes de gestion de base de données tels que le serveur SQL? Nous soulignons quelques différences clés entre SQL et Hadoop.
Qu'est-ce que Hadoop?
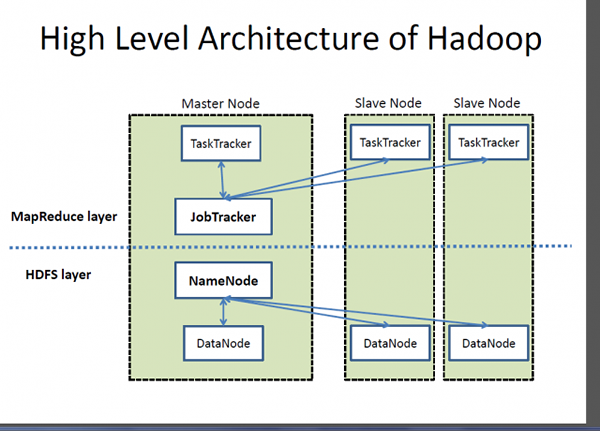
Hadoop est un cadre de traitement distribué open source conçu pour répondre aux besoins des sociétés Web pour indexer et traiter des volumes massifs de données, gracieuseté de la montée croissante des appareils compatibles Internet et la prochaine grande évolution appelée médias sociaux. Google fournit l'inspiration pour le développement qui est devenu connu sous le nom de Hadoop. Il fournit un cadre qui permet le traitement de volumes massifs de données afin de fournir un accès facile et de charger les données dynamiquement.
Qu'est-ce que SQL?
SQL a été l'outil omniprésent pour accéder et manipuler les données dans une base de données. SQ Server n'est plus un système de gestion de base de données régulier utilisé par les développeurs et les administrateurs de base de données et les analystes. Il s'agit d'un énorme écosystème d'outils et de services de différence qui fonctionnent en conjonction pour fournir des tâches de gestion de plate-forme de données très complexes. Il s'agit du langage de facto pour les systèmes transactionnels et d'aide à la décision et les outils d'intelligence commerciale pour accéder à la publicité pour interroger une variété de sources de données. En fait, SQL Server s'occupe de l'application de la qualité et de la cohérence des données que Hadoop.
Différence entre Hadoop et SQL
Outil
- Hadoop est un projet de fondation logicielle Apache et un cadre logiciel de traitement distribué open source pour le stockage et le traitement de l'afflux massif de données et l'exécution d'applications sur des groupes de matériel de base. Hadoop fournit un cadre qui permet le traitement de volumes massifs de données afin de fournir un accès facile et de charger les données dynamiquement. SQL, abréviation de la langue de requête structurée, en revanche, est le langage de facto pour les systèmes transactionnels et d'aide à la décision et les outils de renseignement pour accéder et interroger une variété de données provenant de différentes sources. SQL a été l'outil omniprésent pour accéder, manipuler et stocker des données dans une base de données.
Cadre de Hadoop vs. SQL
- Au cœur de l'écosystème Hadoop se trouvent deux composants principaux - le Hadoop Distributed File System (HDFS) - un système de fichiers distribué, évolutif et portable écrit en Java pour stocker de très grands ensembles de données sur des clusters d'ordinateurs; et une approche du traitement distribué basé sur Java appelé MapReduce. SQL Server, en revanche, est un système de gestion de base de données relationnel et l'une des plates-formes de données les plus puissantes au monde utilisées par un certain nombre de produits commerciaux et internes pour interroger, manipuler et visualiser une variété de sources de données.
Type de données
- Hadoop est conçu pour fonctionner avec n'importe quel type de données, qu'il soit structuré, semi-structuré ou non structuré, ce qui le rend très flexible. SQL, en revanche, est un langage de programmation spécialement créé pour gérer et interroger les données dans les systèmes de gestion de base de données relationnels (RDBM). Il est basé sur le modèle de relation entité des SGBDR, il ne peut donc traiter que des données structurées. SQL ne peut pas être utilisé pour des données non structurées car elles ne sont pas conformes à un modèle de données sans structure facilement identifiable.
Traitement
- Le HDFS est un système de fichiers distribué conçu pour prendre en charge le traitement par lots de la signification des données que les données sont collectées en lots et chaque lot est envoyé pour le traitement. Le lot peut être n'importe quoi d'un jour à une minute. Puisqu'il est conçu pour le traitement par lots, il n'a pas le concept de lectures aléatoires ou d'écritures. SQL Server, au contraire, en tant que plate-forme de base de données à usage général, prend en charge le traitement des données en temps réel, ce qui signifie que les données sont diffusées de l'expéditeur vers le récepteur dès qu'il est produit à l'extrémité source.
Performance de Hadoop et SQL
- L'architecture de Hadoop conduit parfois à un décalage d'impédance entre le stockage des données et l'accès aux données. Il a moins de restrictions ou de validations sur les données qu'il stocke, et il n'a pas les mêmes capacités et écosystèmes de l'utilisateur final que SQL a développé. SQL Server, en revanche, s'occupe de l'application de la qualité et de la cohérence des données beaucoup mieux que Hadoop qui lui permet de tirer parti de l'écosystème de l'analyse des données basée sur SQL et des outils de visualisation des données. Cependant, SQL présente également certains inconvénients, ce qui comprend l'évolutivité pour gérer des quantités massives de données et une prise en charge du stockage de données formatées de manière lâche.
Hadoop VS. SQL: tableau de comparaison

Résumé de Hadoop vs. SQL
Hadoop est l'outil Big Data le plus préféré et le plus accepté conçu pour fonctionner avec n'importe quel type de données - structuré, non structuré ou semi-structuré. Mais en ce qui concerne le SGBDR, SQL est peut-être le système de stockage et de gestion des données le plus puissant, en mémoire et dynamique. Cependant, les solutions de RDBM existantes telles que les serveurs SQL ne consistent qu'à gérer un volume significatif de données, mais pas pour des données non structurées ou semi-structurées avec des attributs variables. Comme pour de nombreuses plates-formes, Hadoop et SQL Server ont tous deux sa juste part des forces et des faiblesses. Utilisez-les tous les deux ensemble et vous pouvez tirer parti des forces de chacun tout en atténuant les faiblesses.
- « Différence entre la reconnaissance vocale et le traitement du langage naturel
- Différence entre le biocapteur et le biochip »