

Différence entre Hadoop et Teradata
- 3475
- 446
- Hugo Marie
Maintenant, plus que jamais, la technologie joue un rôle central dans tout le processus de la façon dont nous collectons et utilisons des données. La technologie a changé la façon dont les données sont produites, traitées et consommées. Alors que le marché de l'analyse du Big Data est rapidement en pleine expansion, de nombreuses entreprises et entreprises commencent à investir dans des technologies de Big Data pour stocker et analyser ces volumes massifs de données. Aujourd'hui, il existe de nombreuses technologies de Big Data sur le marché qui ont un impact sur les nouvelles piles technologiques pour gérer les mégadonnées. Une de ces technologies qui a été au centre des discussions sur les mégadonnées est Apache Hadoop. Hadoop est l'un des plus grands noms de l'industrie du Big Data. Teradata est un système de gestion de base de données relationnel et une solution d'entreposage de données leader qui fournit des solutions de gestion des données pour l'analyse. Il est utilisé pour stocker et traiter une grande quantité de données structurées dans un référentiel central. Vous trouverez ci-dessous une comparaison de la tête à tête entre les deux technologies.
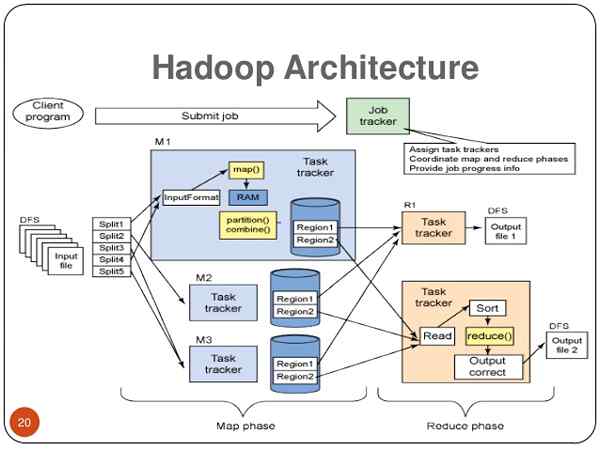
Qu'est-ce que Hadoop?
Hadoop est le cœur du Big Data. Il s'agit d'un cadre logiciel open source développé par Apache Software Foundation et utilisé pour stocker et traiter divers types de données qui permettent aux entreprises basées sur les données de dériver rapidement la valeur complète de toutes leurs données. Hadoop est la réponse pour mettre en œuvre une stratégie de Big Data. Les créateurs originaux de Hadoop sont Doug Cutting et Mike Cafarella. Ils travaillaient sur un projet pour créer un grand index Web appelé «nutch». Ils ont vu les papiers MapReduce et GFS de Google et l'ont trouvé utile pour le projet. Ils ont donc finalement intégré les concepts des articles dans le projet, qui a finalement formé la genèse du projet Hadoop. Doug a donné le nom «Hadoop» à son éléphant jouet, qu'il a utilisé plus tard pour son projet open source. Hadoop stocke des téraoctets et même des pétaoctets de données à peu de frais, sans perdre des données ni interrompre les analyses de données.

Qu'est-ce que Teradata?
Teradata est un système de gestion de base de données relationnel comme Oracle développé par une société de logiciels de premier plan avec le même nom. Teradata est le premier fournisseur mondial de solutions d'analyse commerciale, de solutions de données et d'analyse et de produits et services cloud hybrides. Il fournit le système de gestion de la base de données relationnelle dans un seul MRD qui agit comme un référentiel central. Son SGBDR est considéré comme une solution d'entreposage de données leader qui gère les plus grandes bases de données commerciales au monde. Teradata fournit des capacités de support de décision pour les organisations et les entreprises qui doivent stocker et analyser les gigaoctets et même les téraoctets de données. L'entreprise a été constituée en 1979 et a commencé dans un garage à Brentwood, en Californie,. Le nom Teradata symbolisait la capacité de gérer des milliards d'octets de données. L'entreprise a été fondée par un groupe de personnes.
Différence entre Hadoop et Teradata
Technologie
- Hadoop est une technologie Big Data développée par Apache Software Foundation pour stocker et traiter les applications de Big Data sur des grappes évolutives de matériel de base. Il s'agit d'une plate-forme open source qui relève les défis des mégadonnées impliquant des quantités massives de données trop diverses et en évolution rapide pour les technologies et l'infrastructure conventionnelles pour s'attaquer efficacement. Teradata, en revanche, est un entrepôt de base de données relationnel entièrement évolutif implémenté dans un seul SGBDR qui agit comme un référentiel central. Il s'agit d'une solution d'entreposage de données de premier plan qui gère les plus grandes bases de données commerciales au monde.
Architecture
- Hadoop est basé sur une «architecture maître-esclave», où un cluster comprend un seul nœud maître et tous les autres nœuds sont des nœuds esclaves. L'architecture Hadoop est basée sur trois sous-composants: HDFS (Hadoop Distributed File System), MapReduce et Yarn (encore un autre négociateur de ressources). HDFS est la partie de stockage de l'architecture Hadoop; MapReduce est l'agent qui distribue le travail et recueille les résultats; et le fil alloue les ressources disponibles dans le système.
Teradata est une architecture partagée rien basée sur un système de traitement massivement parallèle (MPP). Le SGBD Teradata est évolutif linéairement et prévisible dans toutes les dimensions d'une charge de travail du système de base de données. Il agit comme un seul magasin de données qui peut accepter un grand nombre de demandes simultanées de plusieurs applications clients. Les principaux composants de Teradata sont l'analyse du moteur, des bynets et des amplis (processeurs de modules d'accès).
Type de données
- Hadoop est utilisé pour stocker et traiter divers types de données qui permettent aux entreprises basées sur les données de dériver rapidement la valeur complète de toutes leurs données. Il peut traiter tout type de données à l'aide de plusieurs outils open source - quel que soit le type de données, qu'il s'agisse de données semi-structurées structurées ou non structurées. Les capacités supérieures de Hadoop pour le traitement des données non structurées sont inégalées. Teradata, en revanche, est une solution d'entreposage de données relationnelle mieux utilisée pour stocker et traiter une grande quantité de données de format tabulaire structuré. Il n'est pas bon pour le traitement des données semi-structurées ou non structurées.
Hadoop VS. Teradata: tableau de comparaison

Résumé de Hadoop vs. Téradata
Hadoop stocke les téraoctets et même les pétaoctets de données à peu de frais, sans perdre de données… il peut traiter n'importe quel type de données en utilisant plusieurs outils open source. Teradata, en revanche, est une solution de gestion de base de données relationnelle entièrement évolutive utilisée pour stocker et traiter une grande quantité de données structurées dans un référentiel central. Hadoop est basé sur une «architecture maître-esclave», où un cluster comprend un seul nœud maître et tous les autres nœuds sont des nœuds esclaves, tandis que Teradata est une architecture partagée basée sur un système de traitement massivement parallèle (MPP).
- « Différence entre excédent et pénurie
- Différence entre les médias sociaux et les médias traditionnels »