

Différence entre HBase et Hive
- 953
- 34
- Lena Pons
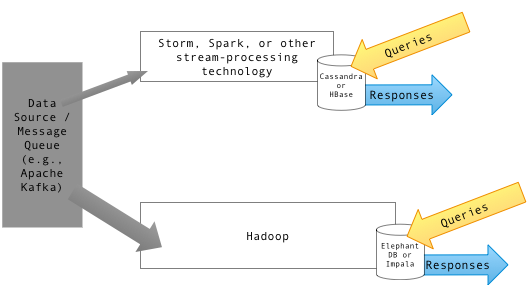
HBASE et HIVE sont tous deux des structures d'entrepôt de données basées sur Hadoop qui diffèrent considérablement quant à la façon dont elles stockent et interrogent les données. La gestion et le traitement d'énormes volumes de données sur le Web deviennent de plus en plus difficiles via des outils de gestion de base de données conventionnels. C'est là que HBASE arrive sur l'image. HBase est un choix préféré pour gérer de grandes quantités de données. Par exemple, si vous devez filtrer dans une énorme réserve d'e-mails pour en retirer un pour l'audit ou à d'autres fins, ce sera un cas d'utilisation parfait pour HBASE. La ruche, en revanche, ressemble plus à un système de rapports d'entrepôt de données traditionnel qui s'exécute au-dessus de Hadoop. Hive propose un langage de requête de type SQL qui vous permet d'interroger les données semi-structurées stockées dans Hadoop. Cela fait l'effort inutile de devoir écrire le code MapReduce. Bien que, HBase et Hive soient utilisés comme magasins de données pour stocker des données non structurées, elles sont différentes.
Qu'est-ce que HBASE?
HBASE est un système de gestion de base de données open source, non relationnel, inspiré de l'architecture de la grande table de Google et écrit en Java. HBASE est fondamentalement une base de données NOSQL distribuée orientée vers une colonne qui s'exécute au-dessus du système de fichiers distribué Hadoop (HDFS). Il est conçu et développé par de nombreux ingénieurs dans le cadre de la Fondation du logiciel Apache. Il se trouve sur Apache Hadoop et alimenté par une structure de fichiers distribuée tolérante à défaut connue sous le nom de HDFS. Il fournit un moyen de stocker des ensembles de données clairsemés, qui sont courants dans les cas d'utilisation du Big Data. Il permet des lectures rapides des données d'accès aléatoire à partir de grandes quantités de données en fonction des valeurs clés. Cependant, il n'est pas conçu pour effectuer des agrégations des données.
Qu'est-ce que la ruche?
Hive n'est pas exactement une base de données mais un package d'entreposage de données construit au sommet de Hadoop. Hive est une technologie différente de HBASE; Il structure les données dans un ensemble de tableaux qui peuvent être joints, agrégés et interrogés sur l'utilisation d'un langage de requête appelé Language de requête Hive (HQL) qui est très similaire au SQL, utilisé pour le traitement par lots des mégadonnées. Il vous permet d'interroger les données semi-structurées stockées à Hadoop, qui est finalement transformée en un travail MapReduce, exécuté localement ou sur un cluster MapReduce distribué. Hive est essentiellement un système d'entrepôt de données pour Hadoop qui facilite la résumé des données faciles, les requêtes ad hoc et l'analyse de grands ensembles de données stockés dans les systèmes de fichiers compatibles Hadoop. Les données peuvent être lues et écrites à partir de Hive et HBase et vice-versa. Cependant, il ne peut pas être utilisé pour le traitement en temps réel des données.
Différence entre HBase et Hive
Technologie
- Bien que HBase et Hive soient tous deux des structures d'entrepôt de données basées sur Hadoop utilisées pour stocker et traiter de grandes quantités de données, elles diffèrent considérablement quant à la façon dont elles stockent et interrogent les données. HBASE est fondamentalement une base de données NOSQL distribuée orientée vers une colonne qui s'exécute au-dessus du système de fichiers distribué Hadoop (HDFS) et fournit un moyen tolérant aux pannes de stocker des ensembles de données clairsemés, qui sont courants dans les cas d'utilisation du Big Data. La ruche, en revanche, n'est pas exactement une base de données mais un package d'entreposage de données construit au sommet de Hadoop. Hive ressemble plus à un système traditionnel de rapports entrepôts de données.
Architecture
- HBase est une base de données NoSQL et une implémentation open source de la grande architecture de table de Google qui se trouve sur Apache Hadoop et alimentée par une structure de fichiers distribuée tolérante à des pannes connue sous le nom de HDFS. Il s'agit d'une solution de stockage évolutive pour s'adapter à une quantité pratiquement infinie de données. Il s'agit d'une architecture de stockage de données utilisée pour stocker des données non structurées. Hive, en revanche, est un moteur SQL construit au-dessus des HDF et exploite MapReduce en interne, permettant d'interroger les données stockées sur HDFS via un langage de requête de type SQL appelé HQL (Language de requête Hive).
Utiliser
- HBASE est utilisé pour construire un service de couche de carreaux à faible coût, flexible et facile à entretenir - Système d'information géographique basée sur Hadoop (HBGIS) - afin d'un stockage massif de données. Il s'agit d'un format de stockage de colonnes sur le disque qui fournit un moyen de stocker des ensembles de données clairsemés, qui sont courants dans les cas d'utilisation du Big Data. Il permet des lectures rapides des données d'accès aléatoire à partir de grandes quantités de données en fonction des valeurs clés. Hive, en revanche, est une norme pour les requêtes SQL sur les pétaoctets de données dans Hadoop et fournit un langage de requête de type SQL appelé HQL pour interroger les données stockées dans un cluster Hadoop.
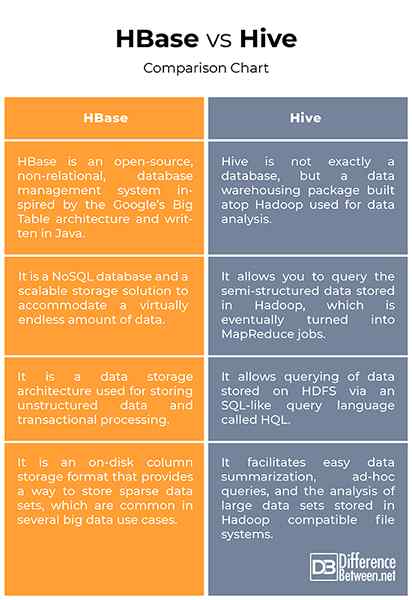
HBASE VS. Ruche: graphique de comparaison
Résumé
Bien que HBase et Hive soient tous deux des structures d'entrepôt de données basées sur Hadoop utilisées pour stocker et traiter de grandes quantités de données, elles diffèrent considérablement quant à la façon dont elles stockent et interrogent les données. HBase est un système de gestion de base de données axé sur la colonne utilisé pour le stockage massif de données et fournit un moyen de stocker des ensembles de données clairsemés, qui sont courants dans plusieurs cas d'utilisation des Big Data. La ruche, en revanche, ressemble plus à un système traditionnel de rapports d'entrepôt de données construit au sommet de Hadoop utilisé pour exécuter le traitement via des travaux de planifications, puis de charger les résultats dans un tableau de type récapitulatif qui peut être interrogé par les applications client.
- « Différence entre le marketing d'influence et le marketing de contenu
- Différence entre Hadoop et MongoDB »