

Différence entre ORC et Parquet
- 2635
- 241
- Théo Roy
Orc et Parquet sont des formats de stockage de fichiers colonnes open source ouverts dans l'écosystème Hadoop et ils sont assez similaires en termes d'efficacité et de vitesse, et surtout, ils sont conçus pour accélérer les charges de travail d'analyse du Big Data. Travailler avec des fichiers ORC est tout aussi simple que de travailler avec des fichiers Parquet en ce qu'ils offrent des capacités de lecture et d'écriture efficaces sur leurs homologues basés sur des lignes. Les deux ont leur juste part des avantages et des inconvénients, et il est difficile de déterminer lequel est le mieux que l'autre. Jetons un meilleur aperçu de chacun d'eux. Nous allons commencer par Orc d'abord, puis passer au parquet.
Orc
Orc, abréviation de la chronique optimisée en ligne, est un format de stockage en colonnes gratuits et open source conçu pour les charges de travail Hadoop. Comme son nom l'indique, ORC est un format de fichier optimisé auto-décrivant qui stocke les données dans des colonnes qui permettent aux utilisateurs de lire et de décompresser uniquement les pièces dont ils ont besoin. Il s'agit d'un successeur du format traditionnel de fichier colonnaire d'enregistrement (RCFILE) conçu pour surmonter les limites des autres formats de fichiers Hive. Il faut beaucoup moins de temps pour accéder aux données et réduit également la taille des données jusqu'à 75%. ORC fournit une façon plus efficace et meilleure de stocker des données pour accéder via des solutions SQL-O-Hadoop telles que Hive à l'aide de TEZ. ORC offre de nombreux avantages par rapport aux autres formats de fichiers Hive tels que une compression de données élevée, des performances plus rapides, une fonctionnalité prédictive Push Down, et plus encore, les données stockées sont organisées en rayures, qui permettent de grandes lectures efficaces de HDFS.
Parquet
Parquet est un autre format de fichiers orienté vers la colonne open source dans l'écosystème Hadoop soutenu par Cloudera, en collaboration avec Twitter. Parquet est très populaire parmi les praticiens du Big Data car il fournit une pléthore d'optimisations de stockage, en particulier dans les charges de travail analytiques. Comme Orc, Parquet fournit des compressions en colonnes vous permettant d'une grande partie d'espace de stockage tout en vous permettant de lire des colonnes individuelles au lieu de lire des fichiers complets. Il offre des avantages importants dans les exigences de performance et de stockage en ce qui concerne les solutions de stockage traditionnelles. Il est plus efficace pour effectuer des opérations de style IO et elle est très flexible lorsqu'il s'agit de soutenir une structure de données imbriquée complexe. En fait, il est particulièrement conçu en gardant à l'esprit les structures de données imbriquées. Parquet est également un meilleur format de fichier pour réduire les coûts de stockage et accélérer l'étape de lecture en ce qui concerne les grands ensembles de données. Parquet fonctionne très bien avec Apache Spark. En fait, c'est le format de fichier par défaut pour l'écriture et la lecture de données dans Spark.
Différence entre ORC et Parquet
Origine
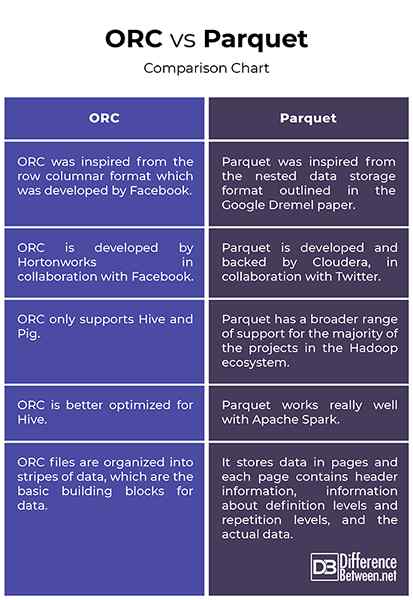
- L'ORC a été inspiré du format en colonnes de ligne qui a été développé par Facebook pour prendre en charge les lectures en colonnes, la poussée prédictive et les lectures paresseuses. Il s'agit d'un successeur du format traditionnel de fichier colonnaire d'enregistrement (RCFILE) et fournit un moyen plus efficace de stocker les données relationnelles que le RCFile, réduisant la taille des données jusqu'à 75%. Parquet, en revanche, a été inspiré du format de stockage de données imbriqué décrit dans le papier Google Dremel et développé par Cloudera, en collaboration avec Twitter. Parquet est maintenant un projet d'incubateur Apache.
Soutien
- ORC et Parquet sont des formats de fichiers de Big Data axés sur les colonnes populaires qui partagent presque une conception similaire en ce que les deux partagent des données dans les colonnes. Alors que Parquet a une gamme de soutien beaucoup plus large à la majorité des projets de l'écosystème Hadoop, Orc ne soutient que Hive et Pig. Une différence clé entre les deux est que l'ORC est mieux optimisé pour Hive, tandis que Parquet fonctionne très bien avec Apache Spark. En fait, Parquet est le format de fichier par défaut pour l'écriture et la lecture des données dans Apache Spark.
Indexage
- Travailler avec des fichiers ORC est tout aussi simple que de travailler avec des fichiers Parquet. Les deux sont parfaits pour les charges de travail lourdes en lecture. Cependant, les fichiers ORC sont organisés en rayures de données, qui sont les blocs de construction de base pour les données et sont indépendants les uns des autres. Chaque bande a un index, des données de ligne et un pied de page. Le pied de page est l'endroit où les statistiques clés de chaque colonne dans une bande telles que le nombre, le min, le max et la somme sont mises en cache. Parquet, en revanche, stocke les données en pages et chaque page contient des informations d'en-tête, des informations sur les niveaux de définition et les niveaux de répétition, et les données réelles.
Orc vs. Parquet: tableau de comparaison
Résumé
Orc et Parquet sont deux des formats de stockage de fichiers orientés vers la colonne open source les plus populaires dans l'écosystème Hadoop conçu pour bien fonctionner avec les charges de travail d'analyse de données. Parquet a été développé par Cloudera et Twitter ensemble pour s'attaquer aux problèmes avec le stockage de grands ensembles de données avec des colonnes élevées. L'ORC est le successeur de la spécification RCFile traditionnelle et les données stockées au format de fichier ORC sont organisées en rayures, qui sont très optimisées pour les opérations de lecture HDFS. Parquet, en revanche, est un meilleur choix en termes d'adaptabilité si vous utilisez plusieurs outils dans l'écosystème Hadoop. Le parquet est mieux optimisé pour une utilisation avec Apache Spark, tandis que Orc est optimisé pour Hive. Mais pour la plupart, les deux sont assez similaires sans différences significatives entre les deux.
- « Différence entre la quarantaine et l'isolement de soi
- Différence entre le crowdsourcing et le financement participatif »