

Différence entre l'exploration de texte et l'exploration de données
- 4012
- 952
- Juliette Paul
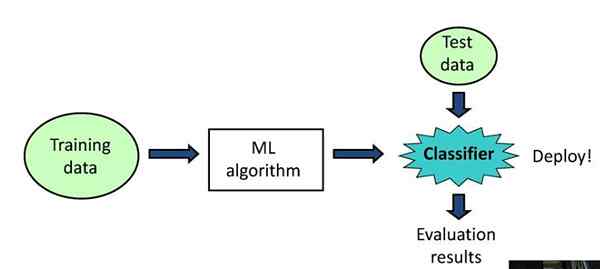
Nous vivons dans une ère numérique où des quantités massives de données sont collectées quotidiennement. Les téraoctets ou les pétaoctets de données sont générés chaque jour. Mais, les données sous sa forme brute ne sont d'aucune utilité, donc l'analyse de ces données est importante. L'exploration de données aide à analyser ces volumes massifs de données en fournissant des outils pour découvrir les connaissances des données. L'extraction de texte est un sous-type d'exploration de données qui transforme les données de texte inexploitées en ressources précieuses.
Qu'est-ce que l'exploration de données?
Semblable à la façon dont le minerai d'or est extrait de la Terre dans sa forme pure par l'exploitation minière, l'exploration de données est le tri et l'extraction d'informations ou de données significatives à partir de grands ensembles de données. L'exploration de données implique généralement d'identifier les tendances ou les modèles de données qui vont généralement au-delà des procédures d'analyse simples à l'aide d'algorithmes logiciels et de méthodes statistiques. Également connue sous le nom de Discovery in Donvery in Data (KDD), l'exploration de données cherche à obtenir des informations précieuses à partir de données afin de répondre aux questions de l'entreprise et de prédire les tendances et le comportement futurs.
Il peut être considéré comme la suite de l'évolution naturelle des technologies de l'information. Autrement dit, l'exploration de données est l'extraction des connaissances à partir des données. Les sources de données peuvent inclure des bases de données, des entrepôts de données, le World Wide Web ou d'autres référentiels d'informations. Il peut être appliqué à essentiellement toutes les formes de données, notamment des données spatiales, des données graphiques ou en réseau, des flux de données, des données ordonnées / séquences et des données de texte.
Qu'est-ce que l'extraction de texte?
L'extraction de texte, également appelée l'exploration de données de texte, est le processus d'extraction des informations ou des informations significatives à partir de données de texte non structurées. Il s'agit d'un sous-type d'exploration de données qui implique du texte - l'un des types de données les plus courants dans les bases de données. Semblable à l'exploration de données, il cherche à extraire des informations utiles à partir de sources de données en identifiant et en explorant les modèles dans les données. Dans l'exploitation de texte, cependant, les sources de données sont limitées au texte. Il filtre de grandes quantités de données de texte et extrait le pertinent dont vous avez besoin.
L'extraction de texte nécessite de structurer le texte d'entrée suivi par l'identification des modèles dans les données structurées, et l'évaluation et l'interprétation de la sortie. Un élément clé de l'exploration de texte est la collecte de documents, qui implique le regroupement de documents textuels. En règle générale, l'extraction de texte implique l'extraction des mots clés, la classification et le clustering, la résumé des documents, la détection d'anomalies et de tendance et les flux de texte.
Différence entre l'exploration de texte et l'exploration de données
Signification
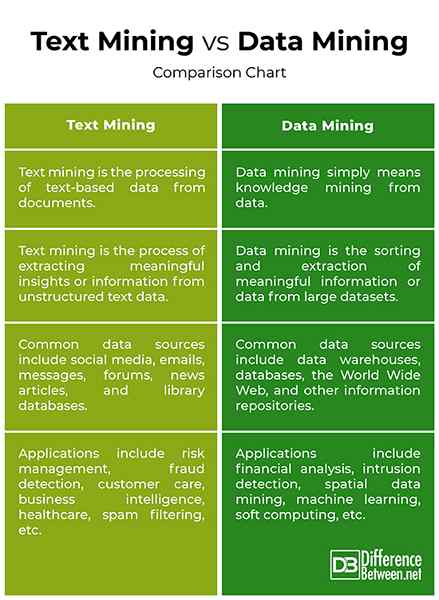
- L'exploration de données est le traitement automatisé de la collecte et de l'analyse de grandes quantités de sources de données afin de trouver des informations significatives ou de découvrir des modèles cachés à partir de données d'une manière qui fournit des informations précieuses. L'exploration de données signifie simplement l'exploration de connaissances à partir des données. L'extraction de texte fait partie de l'exploration de données qui cherche à extraire des informations utiles à partir de sources de données en identifiant et en explorant les modèles dans les données textuelles. L'extraction de texte est le traitement des données texte à partir de documents.
Les sources de données
- Les différentes sources de données utilisées dans le processus d'exploration de données comprennent les entrepôts de données, le World Wide Web, les bases de données transactionnelles, les bases de données multimédias, les bases de données spatiales, les fichiers plats et autres référentiels d'informations. Les sources de données largement utilisées pour l'exploration de texte comprennent des données provenant de sources comme les médias sociaux, les e-mails, les messages, les avis de produits, les forums, les articles de presse, les bases de données de bibliothèque, le grattage Web, etc.
Méthodes d'exploitation
- Les techniques les plus importantes de l'exploration de données sont la collecte et le nettoyage des données, la préparation des données, les modèles de suivi, la classification, l'association, la détection des anomalies, l'analyse de regroupement, l'analyse de régression et la prédiction. Certaines des techniques d'extraction de texte les plus courantes sont la récupération de l'information, la catégorisation de texte, la classification et le clustering, le résumé des documents, l'analyse des sentiments, la détection d'anomalies et de tendance et les flux de texte.
Extraction de texte vs. Exploration de données: tableau de comparaison
Résumé
L'exploration de données signifie le tri et l'extraction d'informations ou de données significatives à partir de grands ensembles de données à des fins de découverte de connaissances. Il existe de nombreux termes avec une signification similaire, par exemple, l'exploration de connaissances à partir des données, la découverte de connaissances, l'extraction des connaissances, l'analyse des données / modèles, etc. Il s'agit d'identifier les tendances ou les modèles dans des données qui vont généralement au-delà des procédures d'analyse simples à l'aide d'algorithmes logiciels et de méthodes statistiques. L'extraction de texte, en revanche, est construite sur diverses approches d'exploration de données pour identifier les tendances des données, sauf dans l'exploitation de texte, l'analyse des données repose sur la collecte de documents. Il utilise les connaissances de base dans une bien plus grande mesure que l'exploration de données.
Qu'est-ce que l'exploitation de texte avec des exemples?
L'extraction de texte identifie les modèles cachés dans les données de texte inexploitées et transforme ces sources de données en informations exploitables. Des exemples d'exploitation de texte comprennent.
Quelle est la différence entre l'exploration de texte et la PNL?
Alors que les deux détiennent la clé pour déverrouiller la valeur commerciale dans les grands ensembles de données, la NLP se concentre sur les ordinateurs de comprendre le comportement humain par le texte, la parole, le sentiment et les actions. L'extraction de texte est simplement d'extraire des informations significatives ou des informations à partir de données de texte non structurées.
La PNL est-elle une exploration de données?
La PNL est un composant de l'exploration de texte qui aide les ordinateurs à traiter et à analyser de grandes quantités de données de texte naturel. Il cherche à extraire des informations à partir de texte, comme l'extraction de texte. La PNL et l'exploration de données sont toutes deux des éléments essentiels en science des données.
Quelle est la comparaison entre l'exploration de textes d'exploration de données et l'exploitation Web?
L'exploration de données est un terme collectif pour l'extraction de texte et l'exploitation Web. L'exploration de données signifie simplement l'exploration de connaissances à partir des données; L'extraction de texte extrait des informations ou des informations significatives à partir de données de texte non structurées; Et l'exploitation Web consiste à utiliser des techniques d'exploration de données pour découvrir des modèles cachés du World Wide Web.
- « Différence entre les connaissances tacites et les connaissances explicites
- Différence entre le tennis et le pickleball »