

Différence entre la tokenisation et le masquage
- 963
- 11
- Mlle Lina Schmitt
L'une des plus grandes préoccupations des organisations traitant de la banque, de l'assurance, de la vente au détail et de la fabrication est la confidentialité des données parce que ces entreprises collectent de grandes quantités de données sur leurs clients. Et ce ne sont pas des données mais des données privées sensibles, qui, lorsqu'elles sont extraites correctement, donnent beaucoup d'informations sur leurs clients. Les entreprises utilisent ces données sur les clients pour prendre de meilleures décisions commerciales telles que la fourniture de services à valeur ajoutée aux clients, ce qui peut entraîner des revenus supplémentaires et une augmentation des bénéfices. Toutes ces données sensibles doivent être protégées en tout temps car elles pourraient être exploitées si elles tombent entre les mauvaises mains. Cela nous amène à notre sujet d'intérêt - la confidentialité des données. En ce qui concerne la confidentialité des données, il existe deux méthodes communes mais efficaces pour protéger les données sensibles - tokenisation et masquage.
Qu'est-ce que la tokenisation?
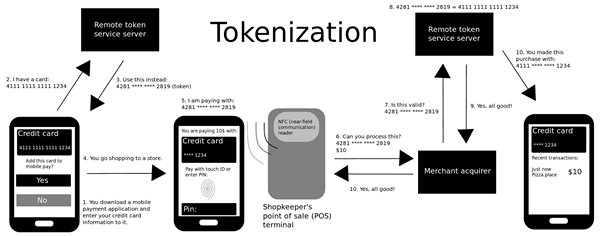
La tokenisation est probablement l'une des plus anciennes techniques utilisées pour garder vos données sécurisées. Parce que la plupart de vos données et informations sont en ligne, comme les portefeuilles numériques, il est essentiel de protéger vos données contre les yeux indiscrets. La tokenisation est une méthode de substitution des données sensibles d'origine avec des espaces réservés non sensibles appelés jetons. L'idée est de remplacer complètement les données d'origine par un substitut qui n'a aucun rapport avec les données d'origine. La technique de la tokenisation est largement utilisée dans l'industrie des cartes de crédit, mais au fil du temps, il est également adopté par d'autres domaines. Ce qu'il fait réellement, c'est garder vos données sensibles telles que votre numéro de carte de crédit dans quelque chose appelé un coffre-fort, qui se trouve essentiellement à l'extérieur du système dans un emplacement sécurisé. Bien que le jeton soit associé à vos données sécurisées, elle est complètement inutile ailleurs. C'est simplement une référence à vos données sensibles et c'est tout.

Qu'est-ce que le masquage?
Le masquage est encore une autre solution efficace pour protéger la confidentialité des données. Comme vous le savez, le volume de données que les organisations doivent gérer se développe à un rythme sans précédent. Et la protection de la confidentialité des données devient un nouveau défi. Le masquage est une technique utilisée pour protéger la confidentialité des données désensibilisées pour l'environnement de production et de test. Il s'agit d'un processus d'obscurcissement, d'anonymisation ou de suppression des données en remplaçant des données sensibles par des caractères aléatoires ou simplement toutes les données non sensibles. Il protège essentiellement vos données sensibles contre les personnes exposées à des personnes qui ne sont pas autorisées à les visualiser ou à y accéder. Le masquage permet aux développeurs d'accéder aux bases de données sécurisées sans risquer une exposition à des informations sensibles. Il existe plusieurs techniques utilisées pour le masquage des données telles que la substitution, le brouillage ou la suppression. Le masquage est souvent utilisé pour protéger les numéros de carte de crédit et autres informations financières sensibles.
Différence entre la tokenisation et le masquage
Technique
- Alors que la tokenisation et le masquage sont de grandes techniques utilisées pour protéger les données sensibles, la tokenisation est principalement utilisée pour protéger les données au repos tandis que le masquage est utilisé pour protéger les données utilisées. La tokenisation est une technique pour remplacer les données originales par des espaces réservés non sensibles appelés jetons. Le jeton n'a aucun sens en dehors du système qui les crée et les relie à d'autres données. L'idée derrière le masquage des données est similaire, mais elle est essentiellement appelée tokenisation permanente. Le masquage cache les données sensibles d'origine en la remplaçant par des caractères aléatoires.
Processus
- La tokenisation prend une valeur telle que le numéro de carte de crédit d'un client et le remplace par une série de nombres générés aléatoirement appelés jetons. C'est là que vous ne pouvez pas revenir à la valeur d'origine car il se trouve commodément en dehors du système dans un emplacement sécurisé. L'idée est de créer une valeur de substitution qui peut être adaptée à la chaîne d'origine à l'aide d'une base de données. Contrairement à la tokenisation, le masquage ne peut pas être inversé un sens une fois que les données sont randomisées à l'aide d'un processus de masquage, il ne peut pas être renversé à son état d'origine.
Cas d'utilisation
- L'utilisation la plus courante de la tokenisation consiste à protéger des informations sensibles ou personnellement identifiables telles que les numéros de carte de crédit, les numéros de sécurité sociale, les numéros de compte, les adresses e-mail, les numéros de téléphone, les numéros de passeport, le numéro de permis de conduire, etc. Le masquage des données, en pratique, est principalement appliqué dans deux domaines d'application, les sauvegardes de la base de données et l'exploration de données. Le masquage peut être idéal lorsque vous avez besoin de se moquer des données sans avoir vu les données d'origine. Cela pourrait être bénéfique à des fins de test ou de profilage. Il existe plusieurs techniques utilisées pour le masquage des données telles que la substitution, le brouillage, le mélange, le chiffrement ou la suppression.
Tokenisation vs. Masquage: tableau de comparaison

Résumé
Les deux sont des techniques couramment utilisées appliquées dans le cadre d'une stratégie complète de confidentialité des données, mais le simple fait de les connaître ne suffit pas à une création d'une architecture de sécurité efficace. Comme l'une des stratégies fondamentales de confidentialité des données existantes, la tokenisation est l'une des méthodes les plus courantes utilisées pour désidentifier les informations sensibles en remplaçant les données d'origine par une valeur non sensible appelée un jeton. Ce jeton est simplement une référence aux données d'origine, mais elle n'a aucune valeur propre. Il ne ressemble qu'à les données d'origine et est mappé aux données d'origine à l'aide d'une base de données. L'idée derrière le masquage des données est similaire, mais la différence réside dans la façon dont ils fonctionnent. Le masquage supprime essentiellement les données en les remplaçant par des caractères aléatoires ou tout simplement toutes les données non sensibles, et cela peut être fait par de nombreuses façons.