

Différence entre les erreurs de type I et de type II
- 4698
- 855
- Lena Pons
 Il existe principalement deux types d'erreurs qui se produisent, tandis que les tests d'hypothèse sont effectués, je.e. Soit le chercheur rejette H0, Quand h0 est vrai, ou il / elle accepte h0 alors en réalité h0 c'est faux. Donc, le premier représente Erreur de type I Et ce dernier est un indicateur de Erreur de type II.
Il existe principalement deux types d'erreurs qui se produisent, tandis que les tests d'hypothèse sont effectués, je.e. Soit le chercheur rejette H0, Quand h0 est vrai, ou il / elle accepte h0 alors en réalité h0 c'est faux. Donc, le premier représente Erreur de type I Et ce dernier est un indicateur de Erreur de type II.
Le test de l'hypothèse est une procédure courante; que les chercheurs utilisent pour prouver la validité, qui détermine si une hypothèse spécifique est correcte ou non. Le résultat des tests est une pierre angulaire pour accepter ou rejeter l'hypothèse nulle (H0). L'hypothèse nulle est une proposition; qui ne s'attend pas à aucune différence ou effet. Une hypothèse alternative (h1) est une prémisse qui attend une différence ou un effet.
Il existe des différences légères et subtiles entre les erreurs de type I et de type II, dont nous allons discuter dans cet article.
Contenu: erreur de type I contre erreur de type II
- Tableau de comparaison
- Définition
- Différences clés
- Résultats possibles
- Conclusion
Tableau de comparaison
| Base de comparaison | Erreur de type I | Erreur de type II |
|---|---|---|
| Signification | L'erreur de type I fait référence à la non-acceptation de l'hypothèse qui doit être acceptée. | L'erreur de type II est l'acceptation de l'hypothèse qui doit être rejetée. |
| Équivalent à | Faux positif | Faux négatif |
| Qu'est-ce que c'est? | C'est un rejet incorrect d'une véritable hypothèse nulle. | C'est une acceptation incorrecte d'une fausse hypothèse nulle. |
| Représente | Un faux coup | Un raté |
| Probabilité de commettre une erreur | Est égal au niveau de signification. | Est égal à la puissance du test. |
| Indiqué par | Lettre grecque 'α' | Lettre grecque 'β' |
Définition de l'erreur de type I
Dans les statistiques, l'erreur de type I est définie comme une erreur qui se produit lorsque les résultats de l'échantillon provoquent le rejet de l'hypothèse nulle, malgré le fait qu'il est vrai. En termes simples, l'erreur d'accepter de l'hypothèse alternative, lorsque les résultats peuvent être attribués au hasard.
Également connu sous le nom d'erreur alpha, il conduit le chercheur à déduire qu'il existe une variation entre deux observances lorsqu'ils sont identiques. La probabilité d'erreur de type I est égale au niveau de signification, que le chercheur établit pour son test. Ici, le niveau de signification fait référence aux chances de faire une erreur de type I.
E.g. Supposons que sur la base des données, l'équipe de recherche d'une entreprise a conclu que plus de 50% du total des clients comme le nouveau service a commencé par la société, ce qui est, en fait, moins de 50%.
Définition de l'erreur de type II
En cas de données, l'hypothèse nulle est acceptée, lorsqu'elle est réellement fausse, alors ce type d'erreur est connu sous le nom d'erreur de type II. Il survient lorsque le chercheur ne nie pas la fausse hypothèse nulle. Il est indiqué par la lettre grecque «bêta (β)» et souvent connu sous le nom d'erreur bêta.
L'erreur de type II est l'échec du chercheur en acceptant une hypothèse alternative, bien qu'elle soit vraie. Il valide une proposition; qui devrait être refusé. Le chercheur conclut que les deux observances sont identiques alors qu'ils ne sont pas.
La probabilité de faire une telle erreur est analogue à la puissance du test. Ici, la puissance du test fait allusion à la probabilité de rejet de l'hypothèse nulle, qui est fausse et doit être rejetée. À mesure que la taille de l'échantillon augmente, la puissance du test augmente également, ce qui entraîne une réduction du risque de faire une erreur de type II.
E.g. Supposons que sur la base des résultats de l'échantillon, l'équipe de recherche d'une organisation affirme que moins de 50% du total des clients comme le nouveau service créé par la société, ce qui est, en fait, supérieur à 50%.
Différences clés entre l'erreur de type I et de type II
Les points ci-dessous sont substantiels en ce qui concerne les différences entre l'erreur de type I et de type II:
- L'erreur de type I est une erreur qui se déroule lorsque le résultat est un rejet de l'hypothèse nulle qui est, en fait, vrai. L'erreur de type II se produit lorsque l'échantillon entraîne l'acceptation de l'hypothèse nulle, qui est en fait fausse.
- Erreur de type I ou autrement connue sous le nom de faux positifs, en substance, le résultat positif équivaut au refus de l'hypothèse nulle. En revanche, l'erreur de type II est également connue sous le nom de faux négatifs, i.e. résultat négatif, conduit à l'acceptation de l'hypothèse nulle.
- Lorsque l'hypothèse nulle est vraie mais rejetée par erreur, c'est une erreur de type I. Par contre, lorsque l'hypothèse nulle est fausse mais acceptée à tort, c'est une erreur de type II.
- L'erreur de type I a tendance à affirmer quelque chose qui n'est pas vraiment présent, je.e. C'est un faux coup. Au contraire, l'erreur de type II échoue dans l'identification de quelque chose, qui est présent, je.e. C'est un manque.
- La probabilité de commettre une erreur de type I est l'échantillon comme niveau de signification. Inversement, la probabilité de commettre une erreur de type II est la même que la puissance du test.
- La lettre grecque 'α' indique l'erreur de type I. Contrairement à l'erreur de type II qui est désignée par la lettre grecque 'β'.
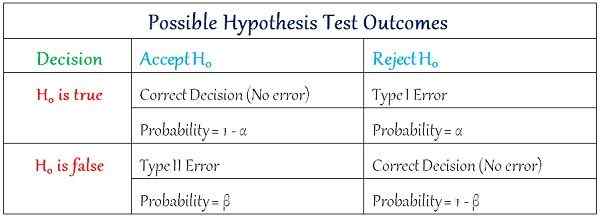
Résultats possibles
Conclusion
Dans l'ensemble, l'erreur de type I augmente lorsque le chercheur remarque une certaine différence, alors qu'en fait, il n'y en a pas, tandis que l'erreur de type II se produit lorsque le chercheur ne découvre aucune différence lorsqu'il y a un. L'occurrence des deux types d'erreurs est très courante car ils font partie du processus de test. Ces deux erreurs ne peuvent pas être supprimées complètement mais peuvent être réduites à un certain niveau.